Paper Club
Generating Effective Learning Environments

1/
We at Vibrant Labs study the literature, old and new, on autoscaling RL environments so we can build better ones.
This week in Paper Club, we went a level deeper: not just what makes a good environment, but what makes a good learning environment, and how to verify that training is working at all.
We covered:
AI-GAs
Agent Psychometrics
The Universal Verifier
2/
Jeff Clune's AI-GAs paper (ahead of its time in 2019, while he was at Uber AI Labs / UWyoming) is one of the foundational pieces on what it actually takes to produce general intelligence automatically.
His argument is that the manual approach to AI (discovering building blocks and engineering them together) is too brittle. The more promising path is an algorithm that learns to generate the conditions for intelligence itself.
The third of his three pillars is what's most relevant to us: automatically generating effective learning environments. It's the least-studied of the three, and arguably the hardest.
3/
The core insight from AI-GAs is that intelligence doesn't require hand-crafted complexity. It emerges from simple rules (e.g., mutation, selection, co-evolution) applied consistently in well-designed environments.
We're doing the same thing, but with LLMs and coding agents instead of evolutionary algorithms. Getting them right is what unlocks everything else.
4/
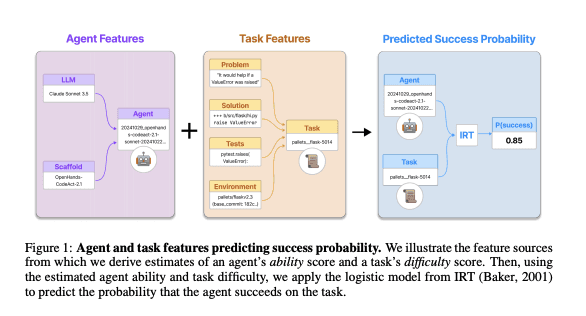
Next up is Agent Psychometrics from the folks at MIT, Fulcrum, and CMU.
The primary question posted here is whether we can if an agent will succeed on a task without running a full rollout?
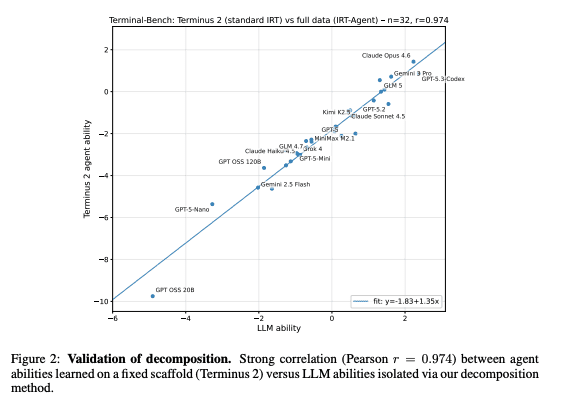
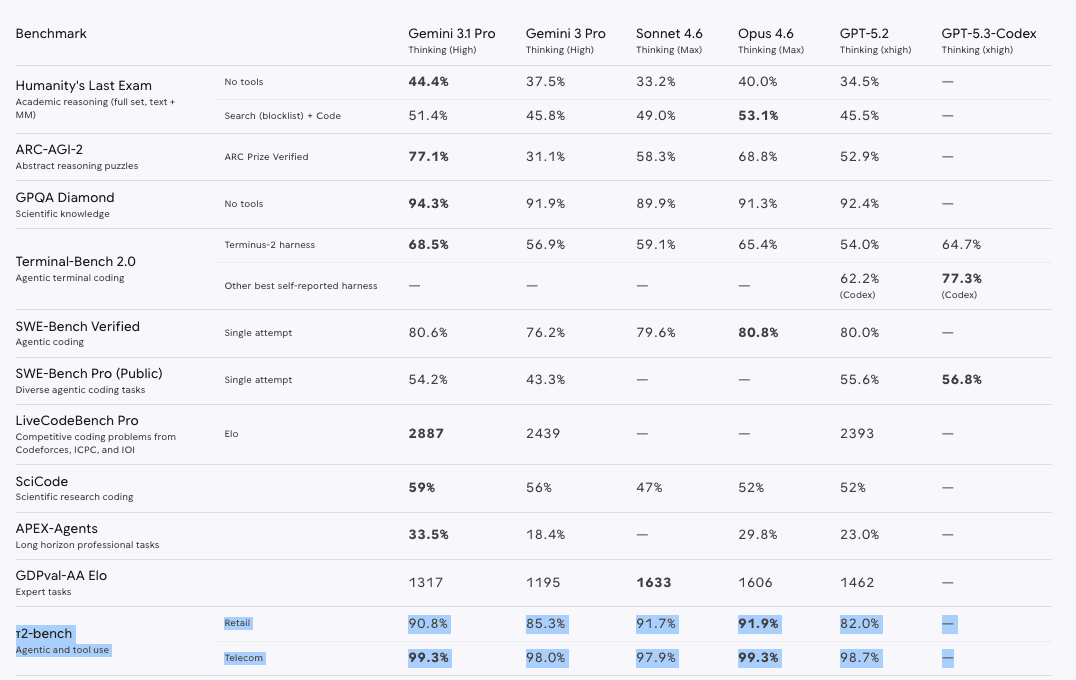
The method involves extending Item Response Theory (essentially the framework behind the SAT) to agentic coding benchmarks. Agent ability is decomposed into two additive components: the underlying LLM and the scaffold (basically the harness). They then predict task difficulty from features like the problem statement, repo state, test patches, and solution patches.
5/
As you might expect, richer agentic features consistently outperform just the problem statement. Generalization is strong for new tasks and new agent combinations but weaker for entirely new benchmarks.
We’ll likely take inspiration from this by running one rollout to calibrate, then using the model to avoid redundant rollouts on expensive runs.
Given what a single run of a frontier model costs at scale, this kind of difficulty prediction could meaningfully cut eval costs.
6/
Last, we covered the Universal Verifier from the folks at Microsoft Research and Browserbase.
Verifying whether a computer use agent actually succeeded is harder than it sounds. Trajectories are long, visually rich, and ambiguous. Getting this wrong corrupts both benchmarks and training signal.
The Universal Verifier is built around 4 principles:
Non-overlapping rubric criteria
Separate process and outcome rewards
Distinguishing controllable vs. uncontrollable failures
Divide-and-conquer screenshot selection to handle long trajectories w/o overwhelming context

7/
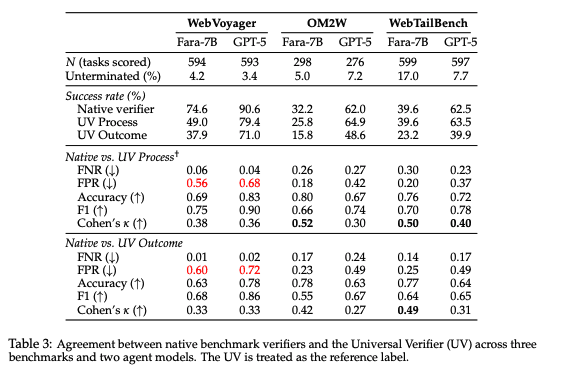
The process/outcome separation stood out to us here.
An agent that navigated correctly to a product that turned out to be out of stock deserves credit for the process even if the outcome failed. Conflating the two either over-penalizes agents for factors outside their control, or lets bad agents off the hook by giving an A for effort.
Separating these items led false positive rates to drop to nearly zero vs. baselines like WebVoyager (≥45%) and WebJudge (≥22%).
8/
All three papers point at the same underlying problem: the quality of the training environment (+ its tasks, its verifiers, and its exploration space) determines the ceiling of what RL training can achieve.
As the Universal Verifier rightly points out, a natural next question from here is whether AI autoresearch agents can replace human annotators in designing verifiers. We’re focused on the same problems. Once the full post-training stack can be handled autonomously, the sky’s the limit.
9/
AI-GAs
Author: Jeff Clune
Agent Psychometrics
Authors: Chris Ge, Daria Kryvosheieva, Daniel Fried, Uzay Girit, Kaivalya Hariharan
Universal Verifier
Authors: Corby Rosset, Pratyusha Sharma, Andrew Zhao, Miguel Gonzalez-Fernandez, Ahmed Awadallah
See discussion →
Multi-turn Tool-Use Benchmarks

1/
Even though Tau2-Bench is a top-tracked multi-turn benchmark by frontier labs, it is nearly saturated across most domains (though banking is an exception).
This type of success is pushing the field toward newer multi-turn benchmarks.
This week in Paper Club, we reviewed two of the strongest recent ones: Vita Bench and WildToolBench.
2/ Both benchmarks utilize seed data (from real platform chats) to generate the full dataset rather than doing everything synthetically.
The benefit of this is that real user trajectories can bring up some divergent behaviors that more simplistic synthetic generation can sometimes miss (like changing intent mid-conversation or using casual “human-like” phrases).
3/ Vita Bench from the team at Meituan covers 3 domains (food delivery, in-store consumption like dining, and an online travel agency) and measures task complexity along 3 axes (reasoning, tool-use, and interaction).
VitaBench involves a fairly complex environment, with 66 tools and 400 tasks (100 across scenarios and 300 for a single scenario).
Even the best frontier models top out around 30% on cross-domain tasks, where the agent has to coordinate across e.g., food delivery and flight booking, simultaneously.
Most errors here are around temporal and spatial reasoning (time zone conversion, travel-to-hotel time, check-in windows) rather than wrong tool calls. The agent has to hold multiple constraints in mind and reason over them simultaneously, which is still more difficult than just executing a workflow.

4/ Two design choices from Vita Bench we want to adopt for our tool-use work (more work to be published soon here!):
Write tasks from the user's perspective with a full user profile attached. This additional context in world-building helps the agent follow realistic patterns. If you give a generic task description to the user simulator, it starts leaking the answer to the agent rather than behaving like a real user.
Inject distractor values into the env so agents can't immediately identify the correct next step.
5/ WildToolBench from the team at Tencent shares some similarities with VitaBench:
It focuses on:
Compositional tasks (that use multiple tool-calls across a complex network)
Implicit intent
Instruction transition (a mix of task queries, clarifications, and casual conversation)
Again, most LLMs perform poorly here, with frontier models achieving ~15% pass.

6/ That said, while VitaBench uses rubric-based evals, WTB matches tool names against a golden tool-chain. In our use case, a hybrid approach could make sense (since just rubric-based loses verifiability and just state-matching can’t capture subgoals).
Overall, though, a concern we have in scaling WTB for our purposes is that it uses pre-written user responses instead of a live simulator, which probably won’t scale as well for RL training. Matching tool names against a golden chain is also a limitation for anything with multiple valid solution paths.

7/
Better benchmarks, better verifiers, and better env coverage.
These are the building blocks for the kind of autonomous, scalable post-training data pipelines we’re building at Vibrant Labs. These are the primary ways we’ll continue moving the needle forward on frontier model performance.
Papers:
VitaBench
Authors: Wei He, Yueqing Sun, Hongyan Hao, Xueyuan Hao, Zhikang Xia, Dunwei Tu, Qi Gu, Chengcheng Han, Dengchang Zhao, Hui Su, Kefeng Zhang, Man Gao, Xi Su, Xiaodong Cai, Xunliang Cai, Yu Yang, Yunke Zhao
WildToolBench
Authors: Peijie Yu, Wei Liu, Yifan Yang, Jinjian Li, Zelong Zhang, Xiao Feng, Feng Zhang
See discussion →
Verifiers & Trustworthy Evals

1/
One of the big challenges on our roadmap at Vibrant Labs is scaling agent benchmarks while maintaining a strong reward signal.
Good verifiers are the bedrock of usable agent benchmarks.
Bad verifiers can inflate model failure rates, and they often hide actual capability gaps.
This week, in Paper Club, we covered SWE-Bench Verified and OSWorld-Verified, which both focus on this topic.
We also covered ComputerRL and BenchGuard for some of the techniques they proposed.

2/
Released in Aug 2024, SWE-Bench Verified attempts to solve several issues with the original (very popular) SWE-Bench:
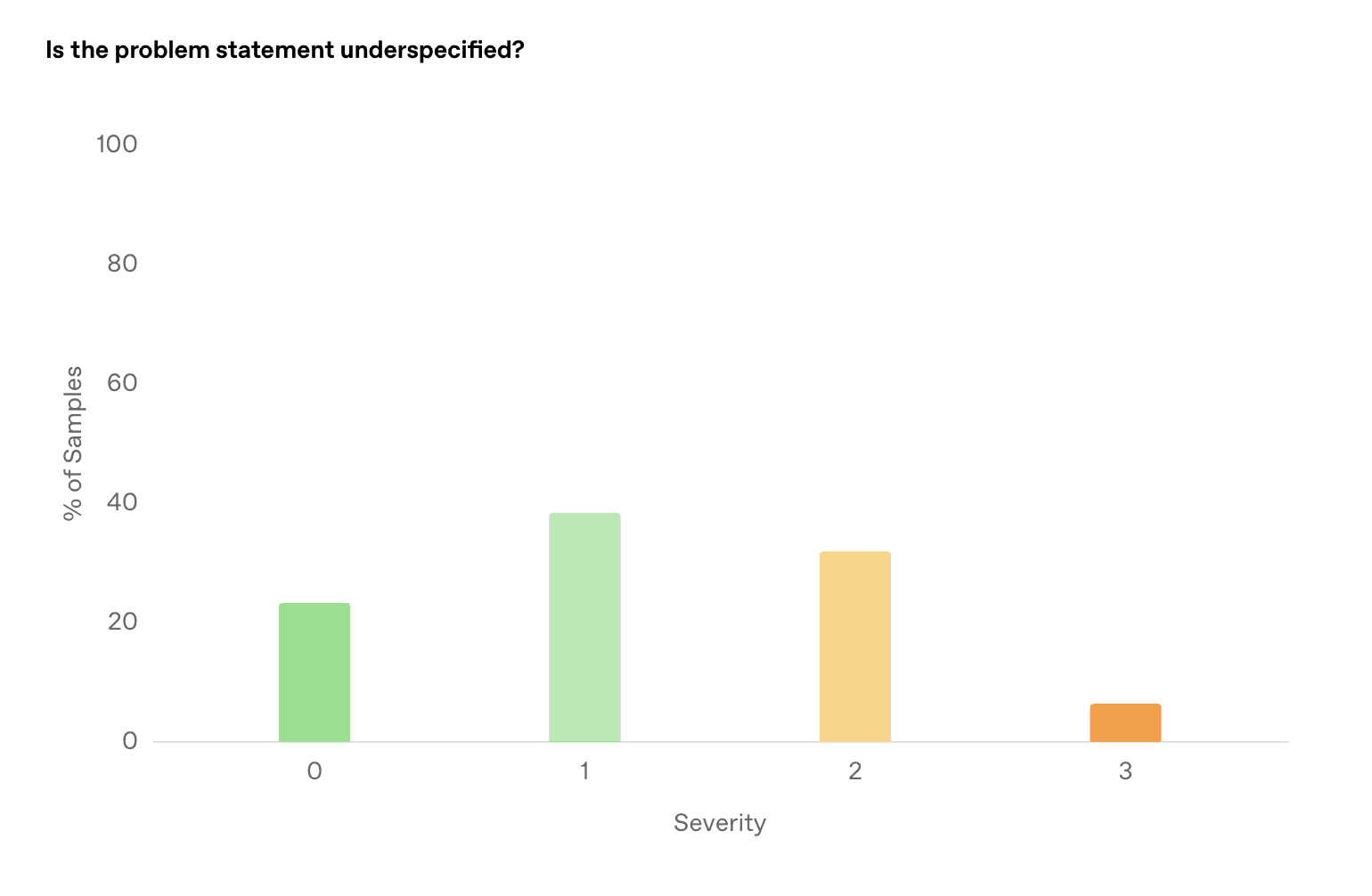
Unit tests were sometimes overspecified (e.g., requiring an exact deprecation message string that the agent couldn’t have known)
Issue descriptions were sometimes underspecified (some context lived in PR discussion threads the agent couldn’t see)
Docker reliability issues caused valid solutions to be graded as incorrect
Obviously, none of these are genuine model failures, they’re limitations of the benchmark and its reward setup.

3/
OpenAI fixed this with a huge human annotation campaign. They coalesced 93 devs across ~1,700 samples and had them rate the samples on:
The quality of the issue description and
The validity of the FAIL_TO_PASS unit tests
Each sample was labeled by multiple annotators independently and they ultimately produced 500 verified samples.
While SWE-Bench Verified is deprecated and saturated/contaminated today (models have seen the OSS code and can now recall exact fixes), it has some utility in its core ideas.
Even <2 years later, the well-specified short tasks that relied on human annotators can be handled by LLMs-as-judges, which is how we will approach this type of problem.
4/
OSWorld-Verified revealed some similar findings, but for CUAs instead of coding agents.
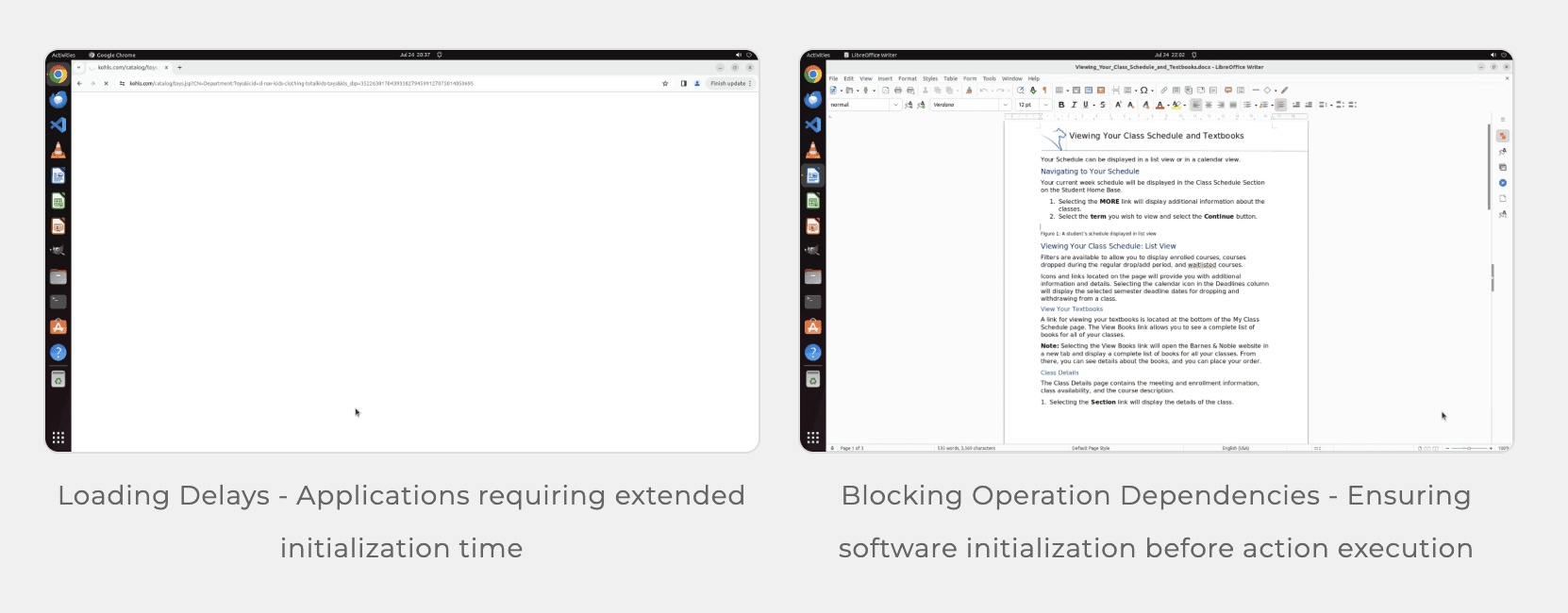
The original OSWorld had problems with:
Uncontrollable env drift (real websites change structure, add bot detection, block network access, etc.)
Flaky task setup (some apps need to boot in a specific state)
Task ambiguity (the verifier didn’t account for multiple valid solution paths)
Again, not actually things the model has control over (esp the latter).

5/
In building this updated benchmark (in July 2025), the team at @ XLangLab fixed the verifiers instead of the tasks (b/c changing a task changes the dataset).
They focused on:
Comparing (fuzzy when needed) final states rather than the trajectory/exact UI
Fixing env/setup-related issues that caused false negatives
A variety of changes to address the env drift (proxy support, better IP handling, some simulated pages instead of the real ones)
Nowadays, OSWorld-Verified is starting to get saturated as well.
This is where we plan to provide better (”verified”) versions of existing CUA gyms/datasets, especially for issues that are known and remain hard. More to come on this front.

6/
ComputerRL from the team at Tsinghua and Z.ai combines GUI actions with API calls, and creates an API-GUI action space that can be used as infra for online RL training.
GUIs are meant for humans, and insisting that agents interact with websites purely through the lens of a human-oriented paradigm has its limitations.
This translation device helped train GLM (AutoGLM-OS-9B) to achieve (then SOTA) 48.9% on OSWorld.
In future work that we’re building in the CUA space, we can take lessons from this research by having an agent still solve a task using the UI, but by having the benchmark use the API/structured state as a task/verifier-mining surface.
This will help us create tasks that are hard for the agent to complete, but easy for the env to grade.

7/
BenchGuard from the teams at the Allen School and Phylo Inc is focused on automatically auditing LLM-driven benchmarks. It reaffirms the notion that there are false failures in many benchmarks that are actually the result of a benchmark issue rather than an agent issue.
They use LLMs to audit various inconsistencies (instructional, environmental, gold-solution-based, and evaluation-logic-based) and classify the defects into a variety of categories.
While this makes sense, benchmark repair can lead to overspecifying tasks. If you keep adding context until the verifier passes, you may leak information that the agent should have found out on its own.
In this realm, we’re also exploring atomic fact decomposition. We plan to break every task instruction into individual facts, then classify each one based on whether or not the agent can look it up in the env.

8/
The next generation of agent benchmarks won’t be won by scale alone; they’ll require significant advancements in verifier quality improvement as well.
We plan to create better reward signal derived from some of the techniques listed above (atomic task decomposition, drift-resistant envs, a collapsed GUI-API action space, continuous QA, etc.).
In doing so, we’ll deliver higher-quality post-training datasets for the next step forward in frontier model capability.
We’ll be releasing datasets that reflect these insights soon. Stay tuned.
9/
Papers:
SWE-Bench Verified
Authors: Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, Carlos E. Jimenez, John Yang, Leyton Ho, Tejal Patwardhan, Kevin Liu, Aleksander Madry
OSWorld-Verified
ComputerRL
Authors: Hanyu Lai, Xiao Liu, Yanxiao Zhao, Han Xu, Hanchen Zhang, Bohao Jing, Yanyu Ren, Shuntian Yao, Yuxiao Dong, Jie Tang
BenchGuard
Authors: Xinming Tu, Tianze Wang, Yingzhou (Minta) Lu, Kexin Huang, Yuanhao Qu, Sara Mostafavi
See discussion →
Gym-Anything: Autoscaling CUA

1/
A month ago, researchers at CMU published Gym-Anything, a paper that directly addresses our core thesis at Vibrant Labs.
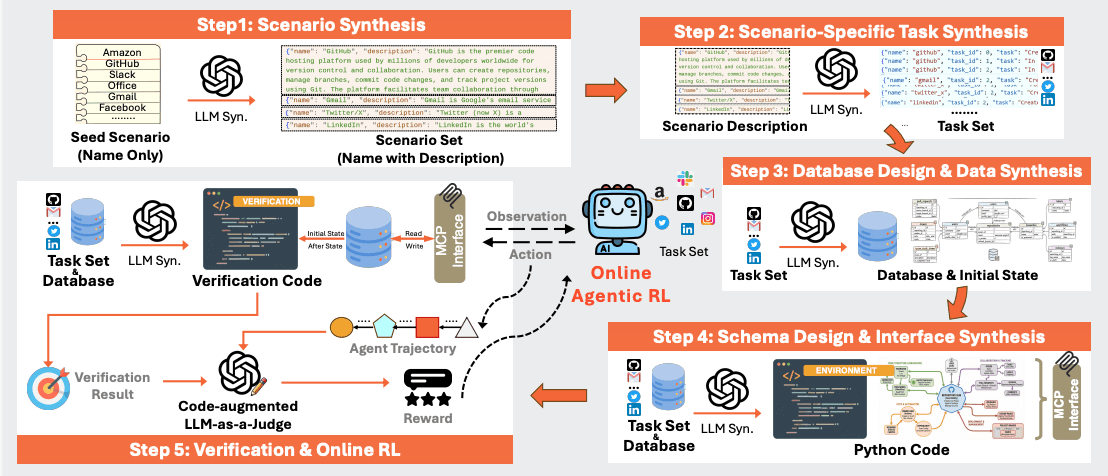
We believe the biggest limiting factor in agent advancement is generating post-training data (envs, tasks, verifiers) at scale.
2/
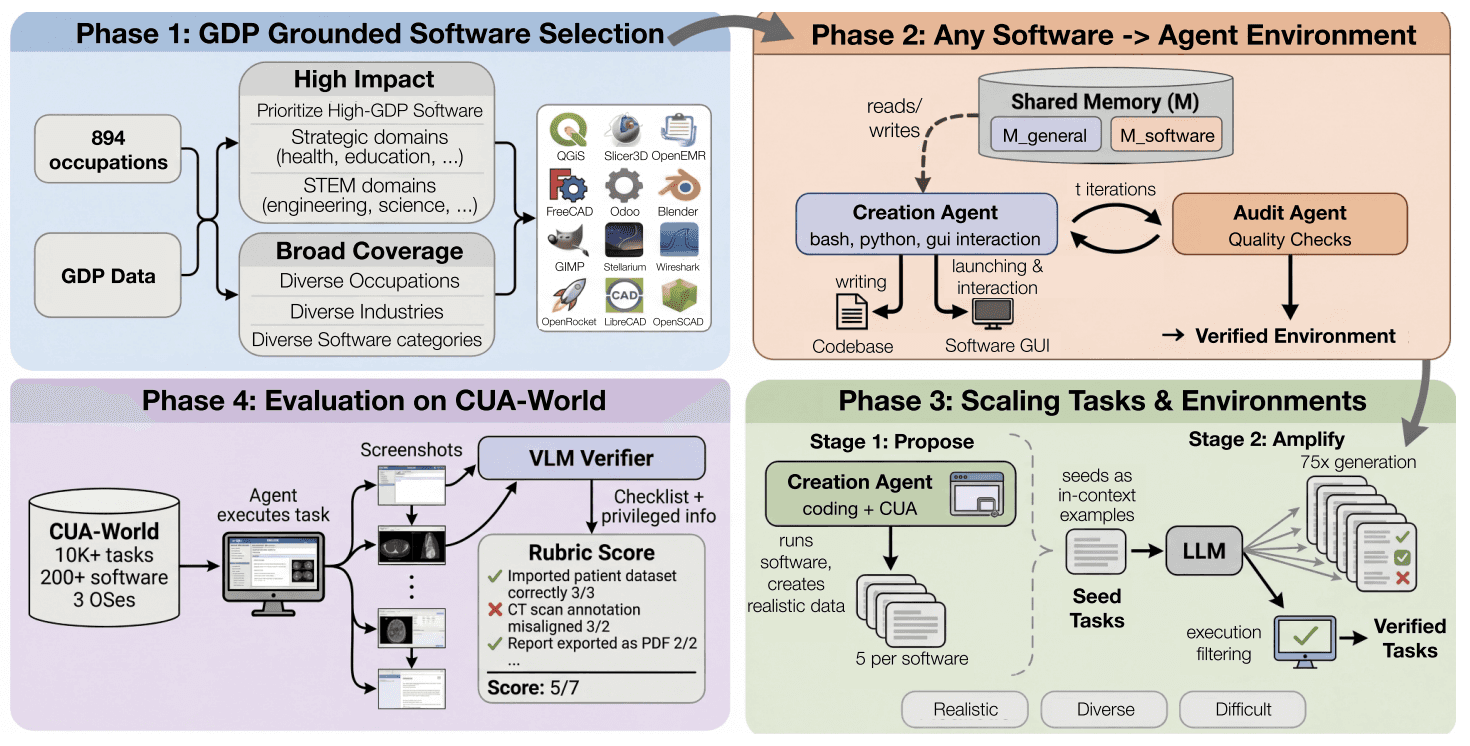
Last week in Paper Club, we read Gym-Anything, in which the authors propose CUA-World, a large, autoscaled collection (10k+) of long-horizon computer-use tasks across a wide variety of knowledge-work and high-GDP enterprise domains (e.g., healthcare, finance, B2B SaaS, etc.).

3/
In CUA-World, the researchers:
Analyzed and selected a set of 200 economically important and diverse softwares
Used a creation agent and an audit agent to turn the real software into an env. The creation agent constructs the env and the audit agent adversarially evaluates the generated env vs the real software. The creation agent also stores its learnings in a shared memory that resummarizes itself regularly.
Autoscaled up tasks with a proposer agent (Opus 4.5/4.6) and an amplifier agent (Gemini 3 Pro). The proposer comes up with 5 difficult, high-standard seed tasks for each env, then the amplifier uses the seed to generate a larger set (75) of varied tasks.
Deduped and filtered the tasks to create CUA-World (and CUA-World-Long for LH tasks)
(Check out how we autoscaled web envs in our previous work, Cloning Bench)
4/
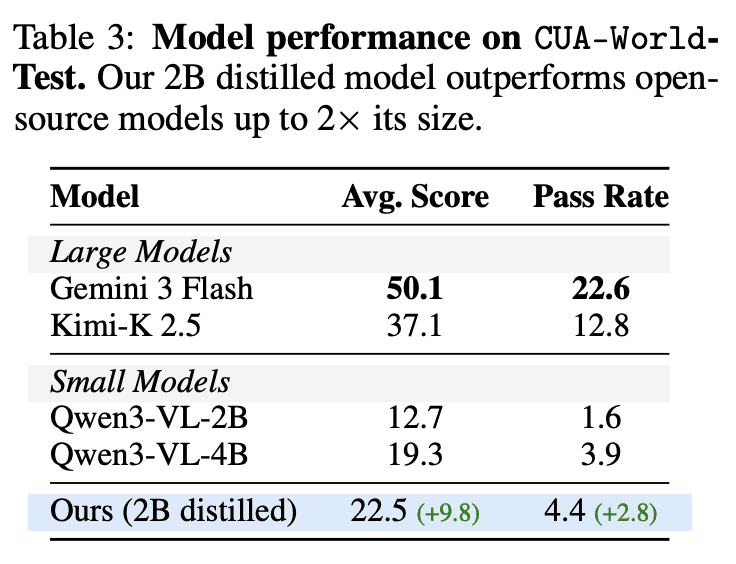
After evaluating large (Gemini 3 Flash, Kimi K2.5, Sonnet 4.6, GPT-5.4) and small (Qwen3-VL-2B, Qwen3-VL-4B) models on the dataset, they found that:
All models perform poorly on CUA-World compared to preexisting web envs like OSWorld and WebArena
Even the large frontier models perform poorly on the long-horizon tasks
Eval improvements after training are still minimal, partially due to poor long-term planning and recovery
In short, real-world tasks are still way more difficult than the manually fabricated ones most RL env companies are building today.

5/
At first, you might think that the minimal post-training improvements are a problem.
But we see some areas of improvement for Gym-Anything that will help accelerate performance.
Simply scaling envs is necessary but insufficient. You need to be scaling specifically high-quality training signal data (with better QA, better verifiers, and better task specification).
6/
The most important piece of this pipeline isn’t the scaling; it’s rigorous QA.
Internally, we’re exploring methods like:
Running the dataset multiple (up to 8) times
Collecting and feeding the trajectories, end state, and verifier outputs back into the model
Ensuring prompts are not underspecified (summarizing and re-feeding the trajectory helps with this)
These techniques have allowed us to identify missed failures and verifier gaps before training runs for envs we’ve shipped to clients.
Also, we should be focusing on tasks that are easy to verify but hard for the agent to do. This materially reduces mistakes that the agent makes.
(7/n)
Gym-Anything gives us a way to generate highly realistic envs and tasks at scale, but this is not enough.
To actually produce large model gains, we need to build a fully self-improving training system (with embedded QA rather than QA afterwards).
That is what produces real hillclimbing (even on long-horizon workflows).
Gym-Anything Paper
Authors: Pranjal Aggarwal, Graham Neubig, https://x.com/wellecks
See discussion →
Failure-driven Task Mining

1/
In the past week, a bunch of people reached out to me wanting to learn more about Tau2-Infinity (our latest benchmark) and the latest Autoscaling RL Environments dinner we hosted in SF.
Every time we at Vibrant Labs preach about synthetic data generation being the biggest bottleneck in AI today, more people join the conversation.
Two counterpoints that are often brought up with autonomously scaling post-training data are:
How do you ensure you’re mining tasks the model genuinely can’t complete?
How do you write verifiers for non-verifiable tasks?
Today, let’s discuss some solutions to these problems.
2/
In last week’s Paper Club, we went deeper into very recently published papers that are focused on these exact topics:
TRACE from the Scaling Intelligence Lab at Stanford
RIFT from Snorkel AI
3/
TRACE primarily focuses on capability-based task mining. In TRACE, the team:
Runs a model on a large set of existing tasks
Labels each trajectory with the capabilities it required (using an LLM)
Clusters the capability descriptions into categories (using an LLM), e.g., trajectories defined as “searching for an item” are together
Selects capabilities that show up in 10%+ of failed trajectories
Calculates the “contrastive gap” (measure of how much the capability was missing in failed vs successful trajectories)
The contrastive gap is an improvement over regular error analysis (just looking at failures) since it reduces the number of false positive capabilities.
It also helps distinguish when the issues are due to model capability gaps vs harness/env problems.
TRACE led to significant gains over the base model on benchmarks like Tau2-Bench.
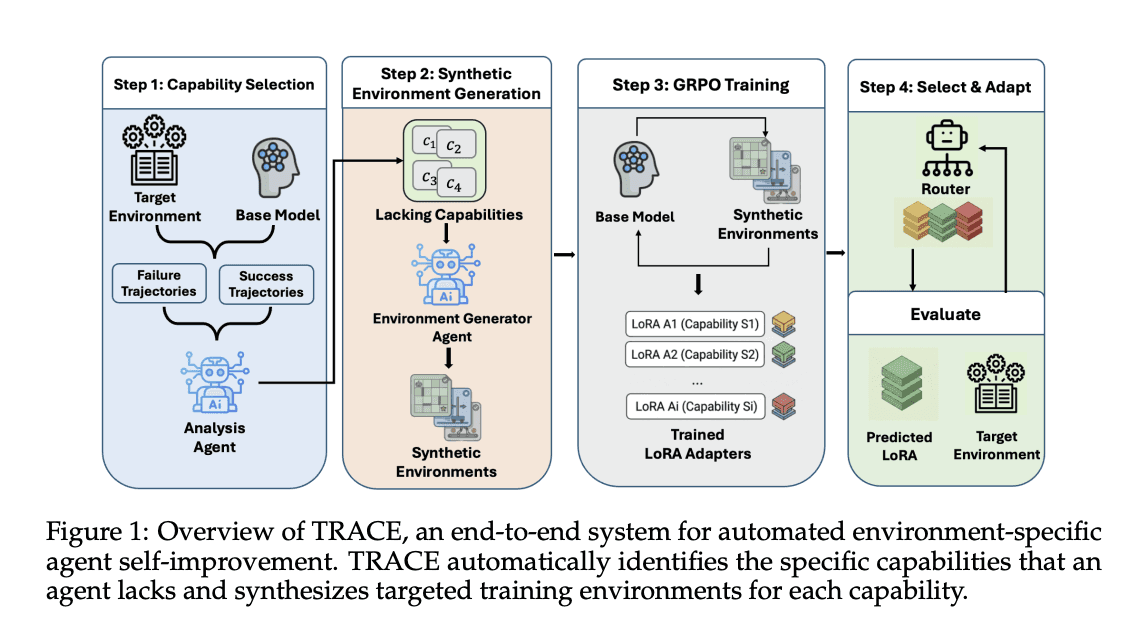
4/
Most suggestions to the non-verifiable task problem involve using an LLM-as-a-judge approach.
RIFT covers what failure modes are likely to occur with LLM-as-a-judge rubrics, and how to surface them.
In RIFT, you run a loop of the same trajectory through the same rubric n times (”reward variance”) across multiple models (”inter-model agreement”). A low variance and high agreement mean the rubric is good.
Since most realistic envs (especially enterprise) have a mix of write-based tasks and read-based tasks, the reward signal is heavily influenced by the reliability of the rubric.
Some of our upcoming work on Tau2-Infinity is heavily rubric-based, and we’ll reference methods like those shared in RIFT in later announcements.
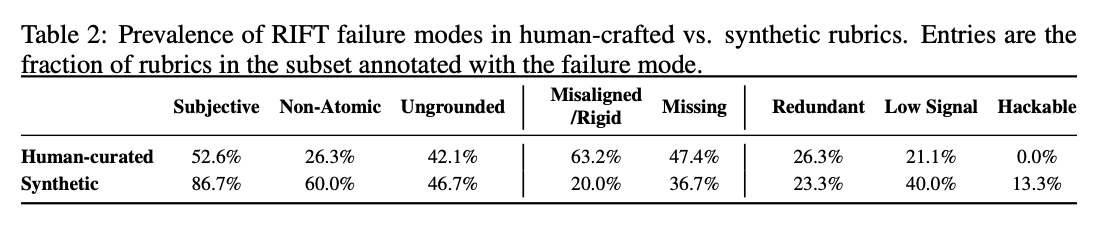
5/
Employing techniques like TRACE and RIFT will help us scale up our tool-use environments like Tau2-Infinity to be more robust, larger synthetic post-training datasets.
TRACE
Authors: Hangoo Kang, Tarun Suresh, Jon Saad-Falcon, Azalia Mirhoseini
RIFT
Authors: Zhengyang Qi, Charles Dickens, Derek Pham, Amanda Dsouza, Armin Parchami, Frederic Sala, Paroma Varma
See discussion →
Tool-Graph Environment Synthesis

1/
I believe that scaling post-training data autonomously will be the next big unlock in frontier model performance, and I’m willing to bet my company on that prediction.
That’s why it’s so important that we at Vibrant Labs spend time reviewing SOTA research from other teams that are autoscaling RL environments.
2/

In Paper Club last week, we covered several papers focused specifically on synthesizing tool-use environments:
Tau-Bench (which recently released Tau3-bench)
EnterpriseOps-Gym
AutoForge
ScaleEnv
Tool-use is still a difficult domain for LLMs since enterprise environments often have a lot of inherent complexities: frequent state changes, stricter access/security guidelines, and many long-horizon workflows.
3/
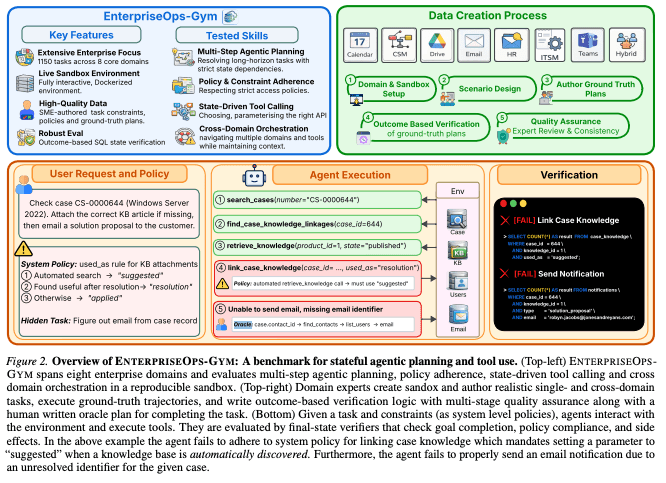

At this point, most people are familiar with Sierra’s Tau-Bench.
Tau-Bench and EnterpriseOps-Gym from ServiceNow and Mila are very similar: both are examples of high-fidelity tool-calling enterprise environments.
Their agents attempt to call various enterprise tools via API to complete tasks across domains (like customer support, HR, meeting scheduling, etc.).
Evaluation is done by comparing the agent’s sequence of tool calls + the final DB state to an equivalent generated by a human expert.
4/
The big drawback with EnterpriseOps-Gym and Tau-Bench is that they both rely on human experts writing 100s of DBs, API endpoints, tasks, and verifiers. It limits the plausible domains and is prone to overfitting. It also won’t scale.
TongyiLab’s AutoForge and ScaleEnv, on the other hand, directly address this problem by proposing that the environments and all of their data should be synthetic.
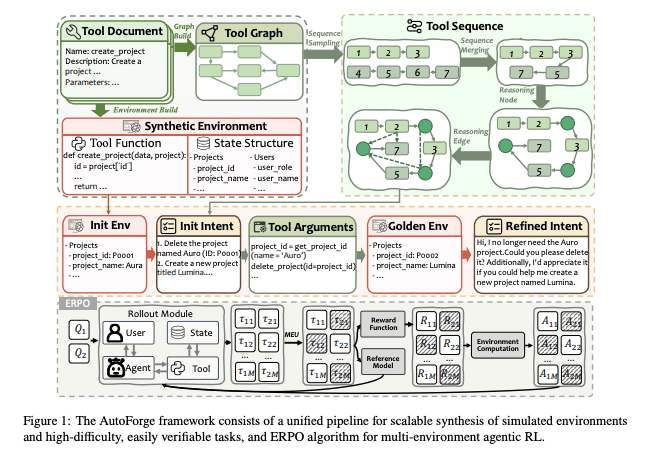

5/
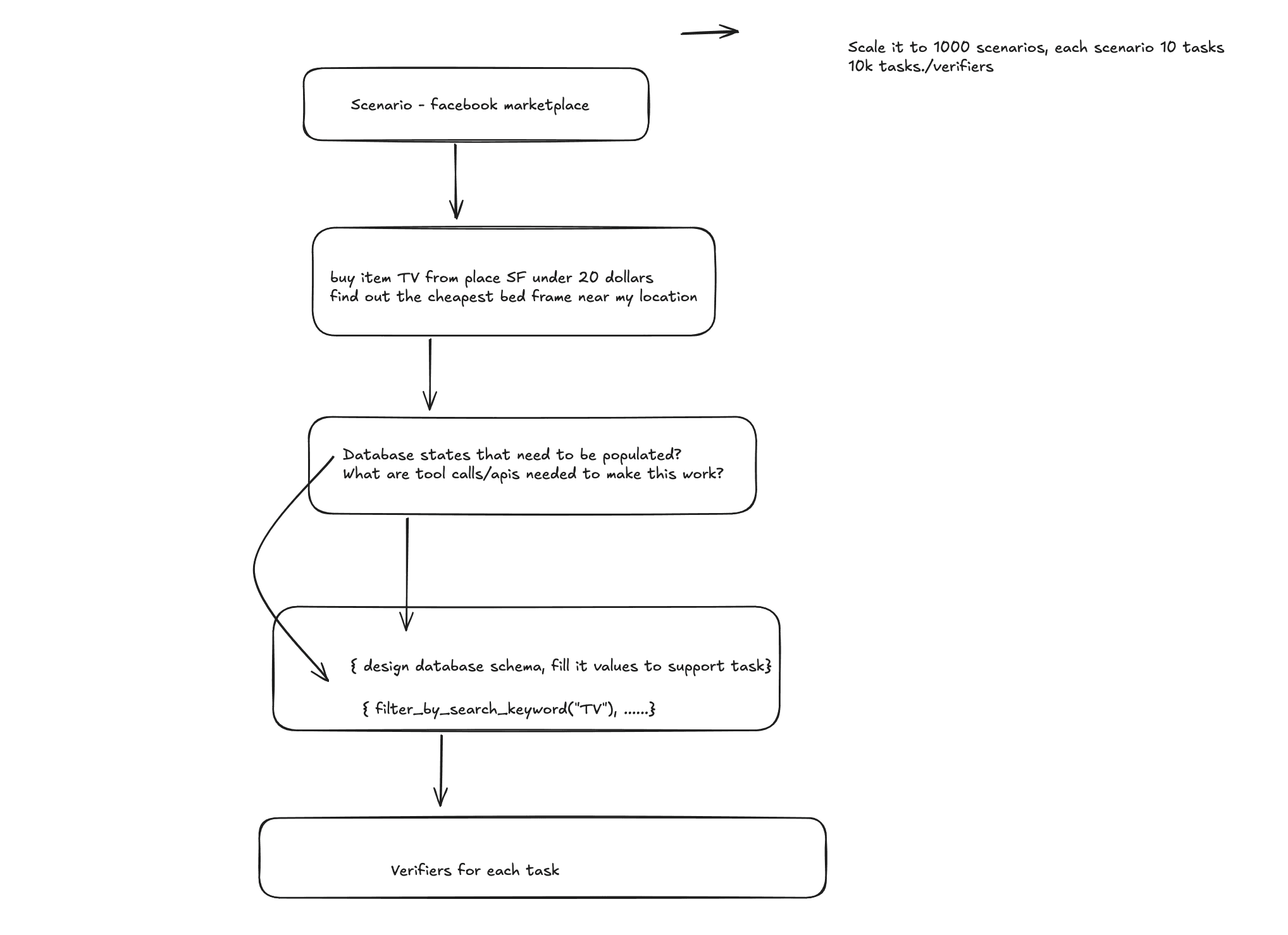
In both ScaleEnv and AutoForge, they follow approaches along these lines:
Start with some seed API docs / the schema of a tool
Build a tool dependency graph of how the tools interact
Do a random (but valid) walk across the tool graph
Remove duplicate walks, and merge walks that could form a longer toolchain
Synthesize the DB state and variables that make the walk/trajectory possible
Derive tasks from the trajectory
Below you can see an example approach I laid out for booking a flight:
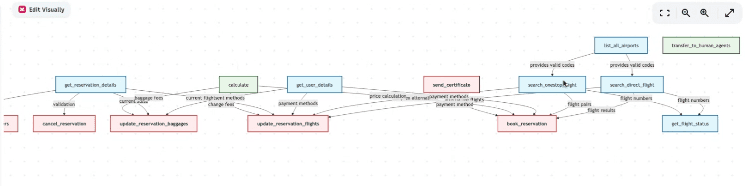
6/
ScaleEnv takes things further by creating a Distractor that injects the DB with data that’s close, but not quite the right answer.
If the task is to “book the cheapest flight from SFO to LAX”, the Distractor inserts multiple flights from SFO to LAX on the same dates with similar prices.
This ensures that the agent actually reasons with logic before moving on to the next tool call.
7/
We’ll be releasing some more data shortly that takes inspiration from all of the above papers (esp AutoForge/ScaleEnv).
Enterprise usage of agents is nascent, but growing quickly, and it’s only a matter of time before someone cracks the code on post-training with the right tool-use data.
Building that kind of data synthetically and autonomously is the answer.
8/
Tau-Bench/Tau2-Bench
Authors: Shunyu Yao, Noah Shinn, Pedram Razavi, Karthik Narasimhan, Victor Barres, Honghua Dong, Soham Ray, Xujie Si
EnterpriseOps-Gym
Authors: Shiva Krishna Reddy Malay, Shravan Nayak, Jishnu Nair, Sagar Davasam, Aman Tiwari, Sathwik Tejaswi, Sridhar Krishna Nemala, Srinivas Sunkara, Sai Rajeswar
AutoForge
Authors: Shihao Cai, Runnan Fang, Jialong Wu, Baixuan Li, Xinyu Wang, Yong Jiang, Liangcai Su, Liwen Zhang, Wenbiao Yin, Zhen Zhang, Fuli Feng, Pengjun Xie, Xiaobin Wang
ScaleEnv
Auhors: Dunwei Tu, Hongyan Hao, Hansi Yang, Yihao Chen, Yi-Kai Zhang, Zhikang Xia, Yu Yang, Yueqing Sun, Xingchen Liu, Furao Shen, Qi Gu, Hui Su, Xunliang Cai
See discussion →
Priorities in LLM-Generated Environments

1/
There are 3 elements to improving models:
Architecture
Compute
Data
No one is changing (1), (2) is actively being solved by the compute giants.
Now what’s left is (3), which has effectively become 2026’s “pickaxes in a gold rush.” Today, the choke point is fully human-created data.
We at Vibrant Labs believe AGI will not be achieved by human data alone, so we’re laser-focused on synthesizing as much as possible to advance models to the next frontier.
2/
Last week in our internal Paper Club, we covered three papers that explore this topic.
Alibaba/Tongyi Lab’s AgentScaler, DeepWisdom/MetaGPT’s AUTOENV, and OMNI all propose methods of using LLMs to synthetically generate environments, tasks, env specifications (harness, etc.) and reward logic.
3/
AgentScaler creates tools, clusters the tools into a dependency graph, then creates scenarios accordingly. Their synthetic env was capable of improving Qwen and other models, but it was still limited to SFT (we’re expanding this to RL runs as well).
4/
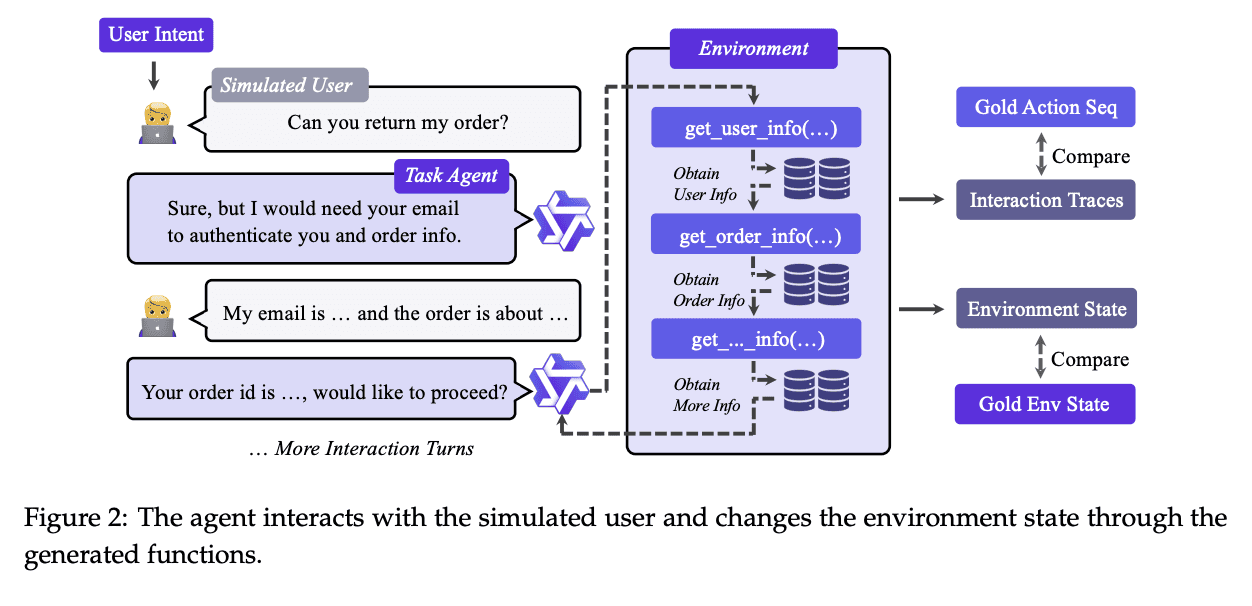
In AUTOENV, the LLM creates a .yaml config then uses it to create action spaces, observation spaces, and rewards in a self-running loop.
Their reliability check method is interesting too - if an older/worse model (ex: Qwen-3.4) consistently has a higher reward score than a newer/better model (ex: GPT-5.4), then they throw out the environment.

5/
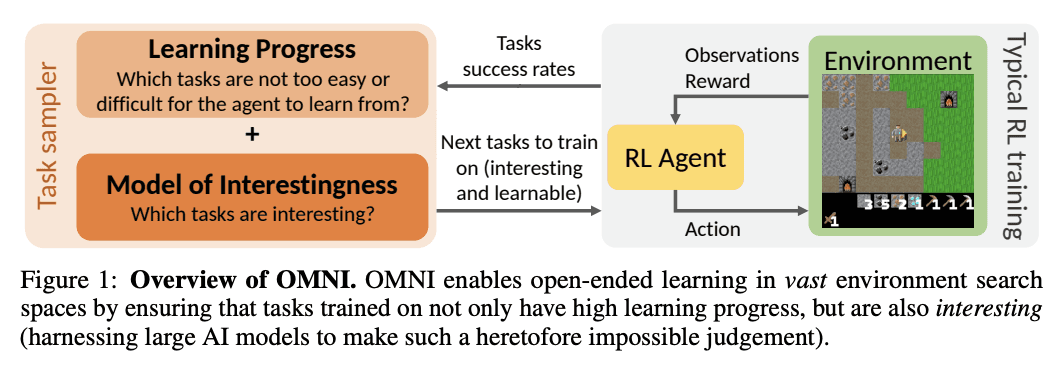
OMNI goes further by quantifying how “interesting” (OMNI) and how “learnable” (LP) these tasks are to humans.
For example, a task like “Go to Gmail, star an email, then delete it” is easily learnable and verifiable, but it is not interesting for humans, and should therefore not be included in RL runs.
We plan to do more research on Open-Endedness here as things progress.
6/
We’re combining some techniques from these studies:
World and scenario generation from AgentScaler
Automatic env design + task and verifier mining from AUTOENV
The notion of human interestingness combined with task learnability from OMNI to sample a subset of all the generated tasks
to properly create synthetic post-training data at scale.
8/ If/when this works, it will dramatically expand the number and diversity of environments frontier models can train inside.
Ultimately, it will help train agents to generalize across many contexts instead of overfitting to a single, limited use case.
Papers:
AUTOENV
Authors: Jiayi Zhang, Yiran Peng, Fanqi Kong, Cheng Yang, Yifan Wu, Zhaoyang Yu, Jinyu Xiang, Jianhao Ruan, Jinlin Wang, Maojia Song, HongZhang Liu, Xiangru Tang, Bang Liu, Chenglin Wu, Yuyu Luo
AgentScaler
Authors: Runnan Fang, Shihao Cai, Baixuan Li, Jialong Wu, Guangyu Li, Wenbiao Yin, Xinyu Wang, Xiaobin Wang, Liangcai Su, Zhen Zhang, Shibin Wu, Zhengwei Tao, Yong Jiang, Pengjun Xie, Fei Huang, Jingren Zhou
OMNI
Authors: Jenny Zhang, Joel Lehman, Kenneth Stanley, Jeff Clune
See discussion →
World Models: High-Fidelity Enterprise Environments

1/
Last week, we did an internal deep dive into enterprise environments/benchmarks like τ²-Bench and CoreCraft. This type of high-fidelity RL env is becoming increasingly popular as frontier labs push their models into more and more agentic capabilities.

2/
Right now, however, the largest bottleneck is human data operations.
For the majority of these envs, time-intensive human labor has been necessary so far to create the world, the synthetic data inside of it, the tasks, and the verifiers needed to do an RL run.
While this has resulted in high-quality data, the human bottleneck is inherently limiting and prevents us from scaling up the number of envs and tasks that could train a model to the fullest extent.
3/
Papers like Snowflake’s AWM, AutoEnv, and Prime Intellect’s τ²-synth have explored creating synthetic data using LLMs to generate their own envs, tasks, and evaluation logic given some basic context. So far, these methods seem to be limited - the environments they produce are simpler than human-designed ones like τ²-Bench and CoreCraft.
4/
At Vibrant Labs, our goal is to recreate something as complex and high-fidelity as CoreCraft, but completely synthetically.
5/
When we can successfully recreate the complexity of envs like CoreCraft without needing extensive human input, we’ll unlock the next stage of model improvement.
See discussion →
World Models for Agents

1/
Yesterday, our internal Paper Club did a deep dive into one of the hottest topics in our industry: world models.
In the past few months, companies like Simile and World Labs have raised huge sums of money to build out world models capable of complex simulations.


2/
This week, we read and discussed APEX-Agents, CoreCraft, and Agent World Model (AWM) to better understand how we can leverage world models to automate environment and task creation.

3/
Mercor's APEX and Surge's CoreCraft are benchmarks testing how well SOTA models can operate in realistic enterprise environments (doing human-created long-horizon tasks in fields like IB, consulting, corporate law, enterprise customer support, etc.).
Snowflake's AWM takes a different approach: instead of handcrafting these envs/tasks, it attempts to mass-scale env creation by feeding an LLM a high-level scenario (see examples below) and instructing the LLM to use the scenario to generate its own tasks, then to build out the necessary components of a world (a database, APIs, reward logic, etc.) from those tasks.


4/
A potential limitation with this approach is that if the initial scenario is too unsophisticated, the tasks the LLM generates will be similarly unexceptional. Even with large environment diversity, AWM’s tasks may not be complex enough to meaningfully challenge a state-of-the-art model.
To successfully automate the creation of high-quality post-training environments and tasks, we’ll make use of a combination of these approaches: we need to build a sufficiently complex world model so that it can create tasks as complex as the human-generated ones in APEX and CoreCraft.
5/
In practice, making agents better at long-horizon tasks will depend highly on how well we can scale the worlds that the models act within.
Papers:
APEX-Agents
EnterpriseBench Corecraft
Agent World Model
Authors
APEX-Agents: Bertie Vidgen, Austin Mann, Abby Fennelly, John Wright Stanly, Lucas Rothman, Marco Burstein, Julien Benchek, David Ostrofsky, Anirudh Ravichandran, Debnil Sur, Neel Venugopal, Alannah Hsia, Isaac Robinson, Calix Huang, Olivia Varones, Daniyal Khan, Michael Haines, Austin Bridges, Jesse Boyle, Koby Twist Zach Richards, Chirag Mahapatra, Brendan Foody, Osvald Nitski
EnterpriseBench Corecraft: Sushant Mehta, Logan Ritchie, Suhaas Garre, Ian Niebres, Nick Heiner, Edwin Chen
Agent World Model: Zhaoyang Wang, Canwen Xu, Boyi Liu, Yite Wang, Siwei Han, Zhewei Yao, Huaxiu Yao, Yuxiong He
See discussion →
SAGE: Hierarchical Exploration for Web Agents

1/ A crucial component of our business is constructing methods for scaling task/verifier creation efficiently without losing realism. This week, we focused on SAGE, which proposes a method of scaling web agent training by using unique data and training recipes inspired by curriculum learning.
2/ With SAGE, the system creates an easy task, then increases task difficulty until the agent fails, then regresses to a simpler task before trying again. It’s like finding the Goldilocks zone for agent learning. With this, SAGE hit 80% of human-level performance. Does that seem too good to be true?
3/ We’re honestly still a bit skeptical that LLMs-as-a-judge can verify complex state-changes as reliably as raw back-end data (especially for production-grade browser agents).
4/ Despite that, the core technique is too sound to ignore. By isolating exactly where a trajectory fails, we can stop throwing away "good enough” data that just needs a specific mid-course correction.
5/ This is a path toward reliably achieving success on long-horizon tasks. If an agent intuitively understands a UI, it can theoretically reverse-engineer a path to a goal human labelers haven't even mapped themselves.
6/ We plan to continue experimentation with the SAGE task-composition method and curriculum training recipes on some of our environments (benchmark coming soon!). If we can apply these learnings correctly, we can scale our training data 10x without human labeling.
7/ SAGE Paper
Authors: Qianlan Yang, Xiangjun Wang, Danielle Perszyk
See discussion →
OS-Genesis: Reverse Task Synthesis

1/
Most UI agent scaling is currently throttled by the cost of human time. OS-Genesis took a much more scalable path by using Reverse Task Synthesis. Instead of recording a user completing a task, they started from a terminal state and worked backwards to hypothesize the intent.
2/
The intuition here is that it’s easier to verify a goal if you already have the state. By starting with the app state and generating the task description, they hit a 91% success rate on trajectory generation.
3/
The jump on AndroidWorld is the part that stood out to us the most. Going from 15.3% to 31.8% just by augmenting with synthetic data suggests we’re nowhere near the ceiling for what small models can do if the data diversity is high enough.
4/
For our work on CUAs, the reverse synthesis logic is a potential fix for the ground truth problem. If you can automate the trajectory, you can train on environments that humans haven’t manually mapped out yet.
5/
At Vibrant Labs, we’re very interested with how synthetic data trajectories will define the next generation of CUAs. If you can automate the training data, you can automate the agent.
See discussion →
Intro

1/ AI social media is currently 90% hype and 10% signal. We’d like to shift that ratio.
2/ At Vibrant Labs, our work lives in the depths of reinforcement learning, post-training data, and computer/browser-use agents. Every day, we internally read and share papers, and we constantly reach out to authors to dig deeper into their findings.
3/ Starting this week, we’re sharing our internal notes. We’ll be breaking down novel research and its implications for autonomous computer use.
4/ If you’re working on benchmarking or post-training agents, stay tuned for the deep dives.
See discussion →
