Tool-Graph Environment Synthesis
1/
I believe that scaling post-training data autonomously will be the next big unlock in frontier model performance, and I’m willing to bet my company on that prediction.
That’s why it’s so important that we at Vibrant Labs spend time reviewing SOTA research from other teams that are autoscaling RL environments.
2/

In Paper Club last week, we covered several papers focused specifically on synthesizing tool-use environments:
Tau-Bench (which recently released Tau3-bench)
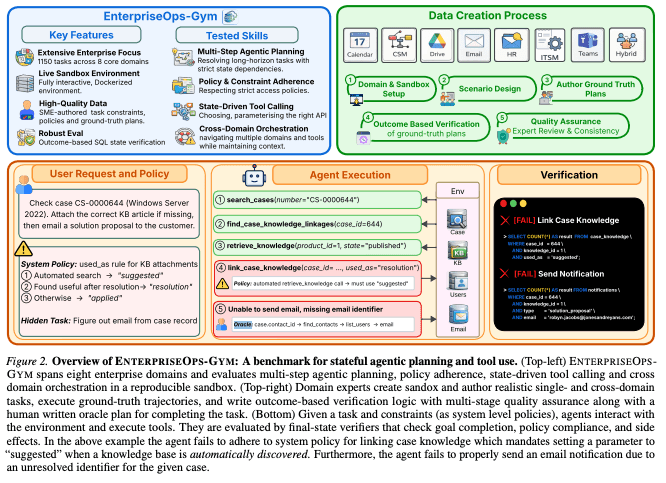
EnterpriseOps-Gym
AutoForge
ScaleEnv
Tool-use is still a difficult domain for LLMs since enterprise environments often have a lot of inherent complexities: frequent state changes, stricter access/security guidelines, and many long-horizon workflows.
3/

At this point, most people are familiar with Sierra’s Tau-Bench.
Tau-Bench and EnterpriseOps-Gym from ServiceNow and Mila are very similar: both are examples of high-fidelity tool-calling enterprise environments.
Their agents attempt to call various enterprise tools via API to complete tasks across domains (like customer support, HR, meeting scheduling, etc.).
Evaluation is done by comparing the agent’s sequence of tool calls + the final DB state to an equivalent generated by a human expert.
4/
The big drawback with EnterpriseOps-Gym and Tau-Bench is that they both rely on human experts writing 100s of DBs, API endpoints, tasks, and verifiers. It limits the plausible domains and is prone to overfitting. It also won’t scale.
TongyiLab’s AutoForge and ScaleEnv, on the other hand, directly address this problem by proposing that the environments and all of their data should be synthetic.
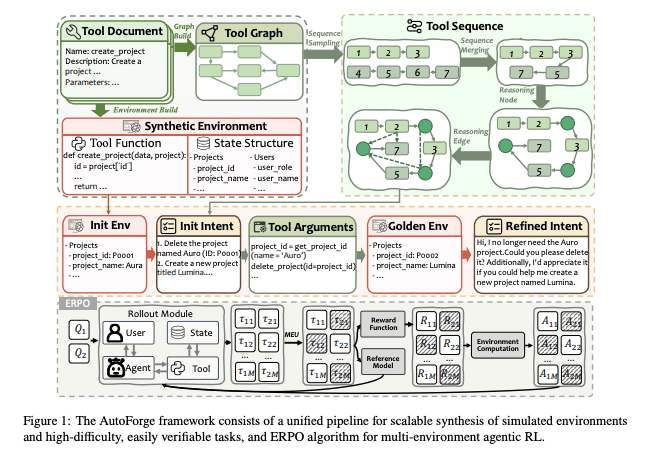

5/
In both ScaleEnv and AutoForge, they follow approaches along these lines:
Start with some seed API docs / the schema of a tool
Build a tool dependency graph of how the tools interact
Do a random (but valid) walk across the tool graph
Remove duplicate walks, and merge walks that could form a longer toolchain
Synthesize the DB state and variables that make the walk/trajectory possible
Derive tasks from the trajectory
Below you can see an example approach I laid out for booking a flight:
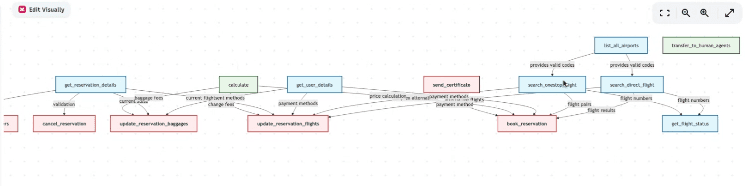
6/
ScaleEnv takes things further by creating a Distractor that injects the DB with data that’s close, but not quite the right answer.
If the task is to “book the cheapest flight from SFO to LAX”, the Distractor inserts multiple flights from SFO to LAX on the same dates with similar prices.
This ensures that the agent actually reasons with logic before moving on to the next tool call.
7/
We’ll be releasing some more data shortly that takes inspiration from all of the above papers (esp AutoForge/ScaleEnv).
Enterprise usage of agents is nascent, but growing quickly, and it’s only a matter of time before someone cracks the code on post-training with the right tool-use data.
Building that kind of data synthetically and autonomously is the answer.
8/
Authors: Shunyu Yao, Noah Shinn, Pedram Razavi, Karthik Narasimhan, Victor Barres, Honghua Dong, Soham Ray, Xujie Si
Authors: Shiva Krishna Reddy Malay, Shravan Nayak, Jishnu Nair, Sagar Davasam, Aman Tiwari, Sathwik Tejaswi, Sridhar Krishna Nemala, Srinivas Sunkara, Sai Rajeswar
Authors: Shihao Cai, Runnan Fang, Jialong Wu, Baixuan Li, Xinyu Wang, Yong Jiang, Liangcai Su, Liwen Zhang, Wenbiao Yin, Zhen Zhang, Fuli Feng, Pengjun Xie, Xiaobin Wang
Auhors: Dunwei Tu, Hongyan Hao, Hansi Yang, Yihao Chen, Yi-Kai Zhang, Zhikang Xia, Yu Yang, Yueqing Sun, Xingchen Liu, Furao Shen, Qi Gu, Hui Su, Xunliang Cai
