Multi-turn Tool-Use Benchmarks
1/
Even though Tau2-Bench is a top-tracked multi-turn benchmark by frontier labs, it is nearly saturated across most domains (though banking is an exception).
This type of success is pushing the field toward newer multi-turn benchmarks.
This week in Paper Club, we reviewed two of the strongest recent ones: Vita Bench and WildToolBench.
2/ Both benchmarks utilize seed data (from real platform chats) to generate the full dataset rather than doing everything synthetically.
The benefit of this is that real user trajectories can bring up some divergent behaviors that more simplistic synthetic generation can sometimes miss (like changing intent mid-conversation or using casual “human-like” phrases).
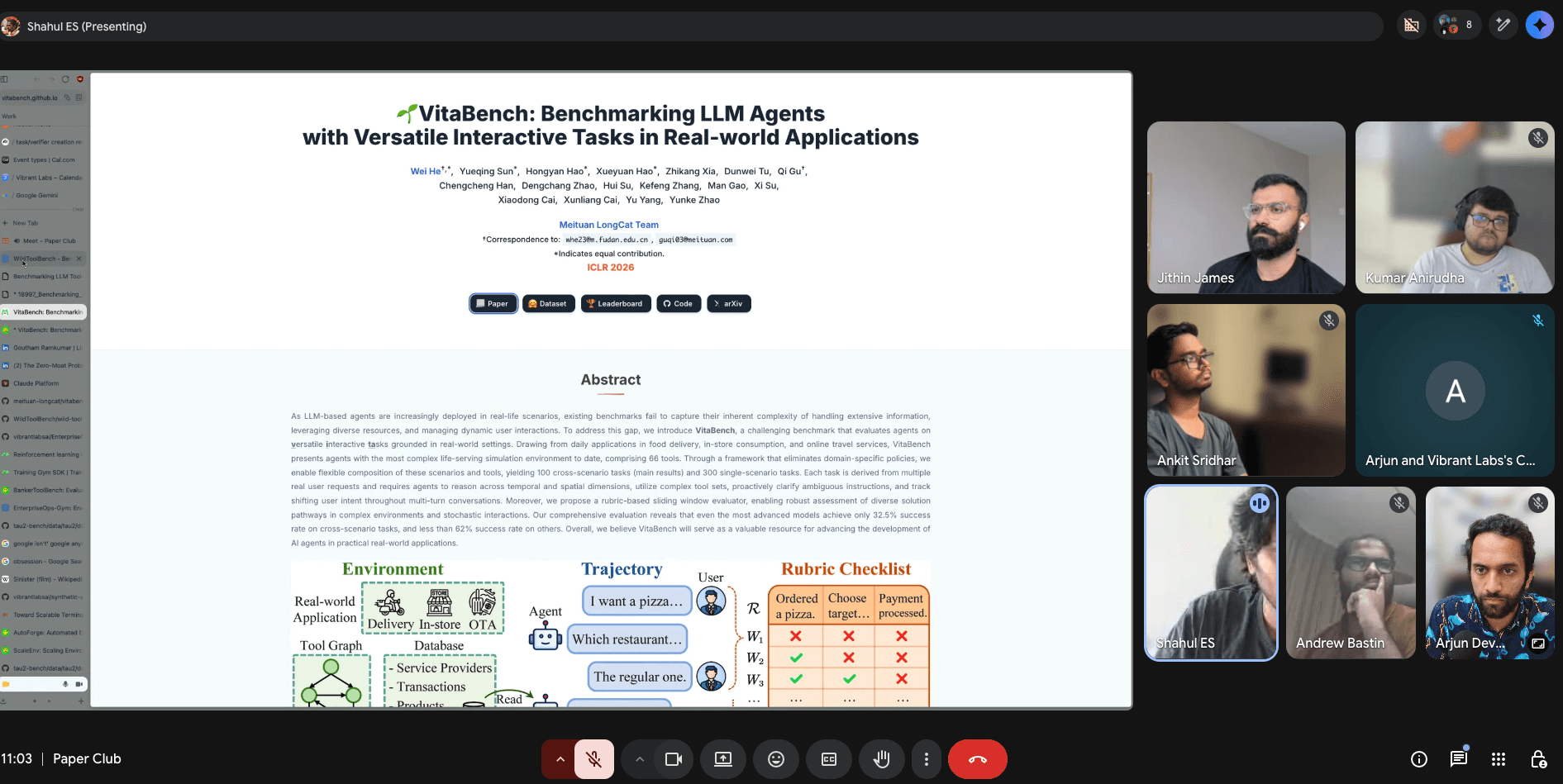
3/ Vita Bench from the team at Meituan covers 3 domains (food delivery, in-store consumption like dining, and an online travel agency) and measures task complexity along 3 axes (reasoning, tool-use, and interaction).
VitaBench involves a fairly complex environment, with 66 tools and 400 tasks (100 across scenarios and 300 for a single scenario).
Even the best frontier models top out around 30% on cross-domain tasks, where the agent has to coordinate across e.g., food delivery and flight booking, simultaneously.
Most errors here are around temporal and spatial reasoning (time zone conversion, travel-to-hotel time, check-in windows) rather than wrong tool calls. The agent has to hold multiple constraints in mind and reason over them simultaneously, which is still more difficult than just executing a workflow.

4/ Two design choices from Vita Bench we want to adopt for our tool-use work (more work to be published soon here!):
Write tasks from the user's perspective with a full user profile attached. This additional context in world-building helps the agent follow realistic patterns. If you give a generic task description to the user simulator, it starts leaking the answer to the agent rather than behaving like a real user.
Inject distractor values into the env so agents can't immediately identify the correct next step.
5/ WildToolBench from the team at Tencent shares some similarities with VitaBench:
It focuses on:
Compositional tasks (that use multiple tool-calls across a complex network)
Implicit intent
Instruction transition (a mix of task queries, clarifications, and casual conversation)
Again, most LLMs perform poorly here, with frontier models achieving ~15% pass.

6/ That said, while VitaBench uses rubric-based evals, WTB matches tool names against a golden tool-chain. In our use case, a hybrid approach could make sense (since just rubric-based loses verifiability and just state-matching can’t capture subgoals).
Overall, though, a concern we have in scaling WTB for our purposes is that it uses pre-written user responses instead of a live simulator, which probably won’t scale as well for RL training. Matching tool names against a golden chain is also a limitation for anything with multiple valid solution paths.

7/
Better benchmarks, better verifiers, and better env coverage.
These are the building blocks for the kind of autonomous, scalable post-training data pipelines we’re building at Vibrant Labs. These are the primary ways we’ll continue moving the needle forward on frontier model performance.
Papers:
Authors: Wei He, Yueqing Sun, Hongyan Hao, Xueyuan Hao, Zhikang Xia, Dunwei Tu, Qi Gu, Chengcheng Han, Dengchang Zhao, Hui Su, Kefeng Zhang, Man Gao, Xi Su, Xiaodong Cai, Xunliang Cai, Yu Yang, Yunke Zhao
Authors: Peijie Yu, Wei Liu, Yifan Yang, Jinjian Li, Zelong Zhang, Xiao Feng, Feng Zhang
