Gym-Anything: Autoscaling CUA
1/
A month ago, researchers at CMU published Gym-Anything, a paper that directly addresses our core thesis at Vibrant Labs.
We believe the biggest limiting factor in agent advancement is generating post-training data (envs, tasks, verifiers) at scale.
2/
Last week in Paper Club, we read Gym-Anything, in which the authors propose CUA-World, a large, autoscaled collection (10k+) of long-horizon computer-use tasks across a wide variety of knowledge-work and high-GDP enterprise domains (e.g., healthcare, finance, B2B SaaS, etc.).

3/
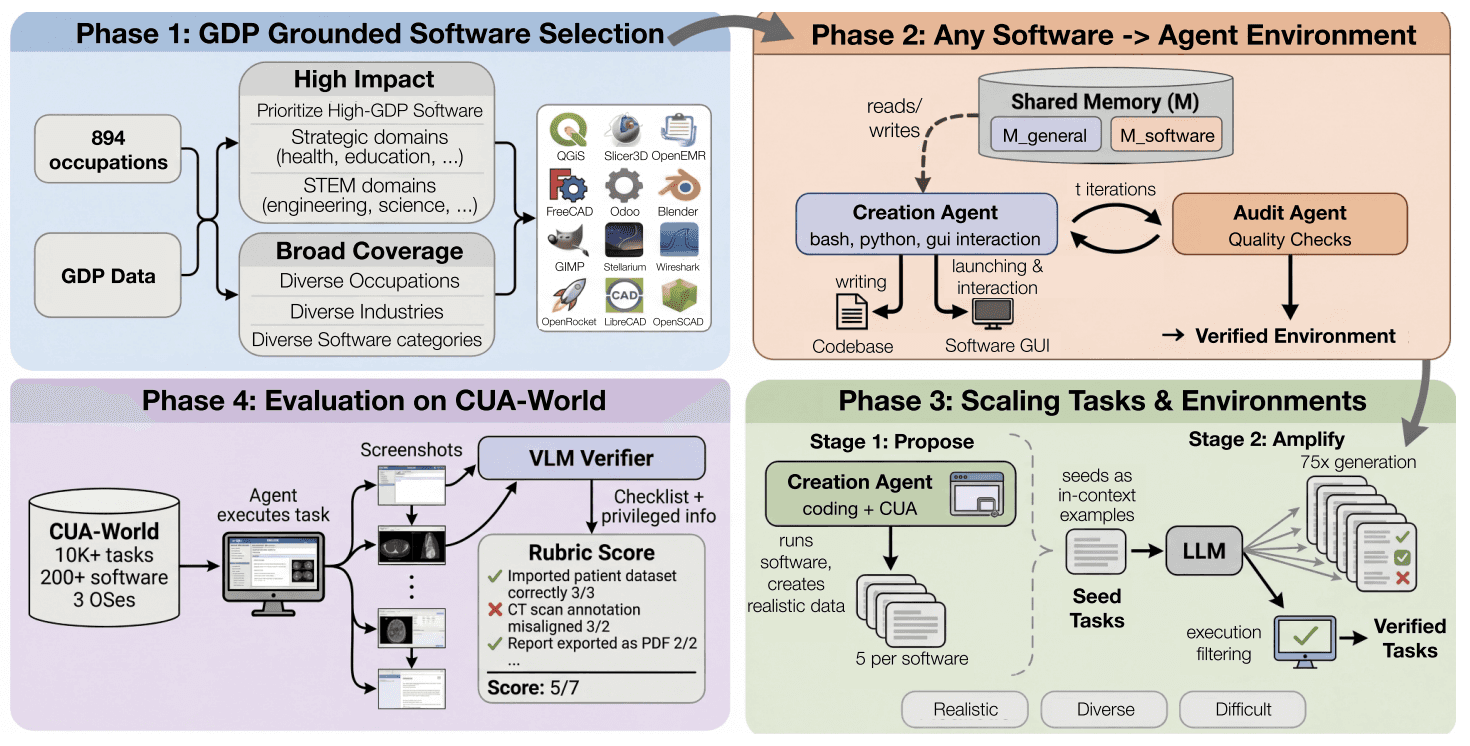
In CUA-World, the researchers:
Analyzed and selected a set of 200 economically important and diverse softwares
Used a creation agent and an audit agent to turn the real software into an env. The creation agent constructs the env and the audit agent adversarially evaluates the generated env vs the real software. The creation agent also stores its learnings in a shared memory that resummarizes itself regularly.
Autoscaled up tasks with a proposer agent (Opus 4.5/4.6) and an amplifier agent (Gemini 3 Pro). The proposer comes up with 5 difficult, high-standard seed tasks for each env, then the amplifier uses the seed to generate a larger set (75) of varied tasks.
Deduped and filtered the tasks to create CUA-World (and CUA-World-Long for LH tasks)
(Check out how we autoscaled web envs in our previous work, Cloning Bench)
4/
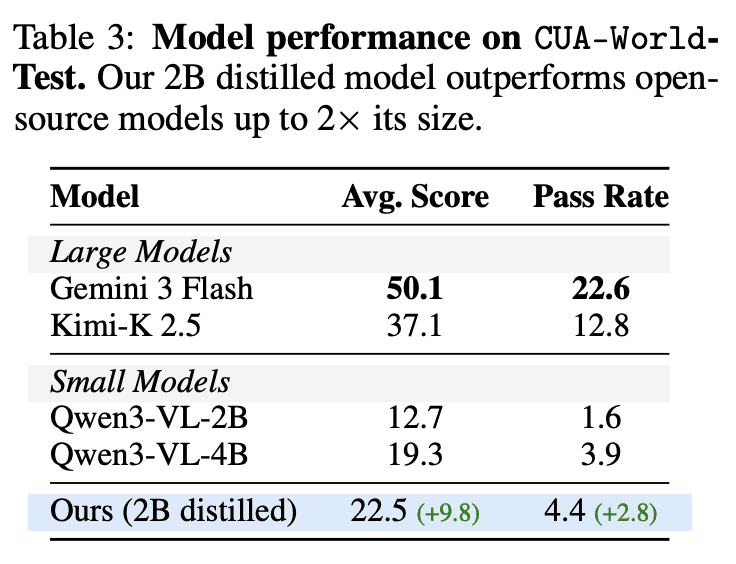
After evaluating large (Gemini 3 Flash, Kimi K2.5, Sonnet 4.6, GPT-5.4) and small (Qwen3-VL-2B, Qwen3-VL-4B) models on the dataset, they found that:
All models perform poorly on CUA-World compared to preexisting web envs like OSWorld and WebArena
Even the large frontier models perform poorly on the long-horizon tasks
Eval improvements after training are still minimal, partially due to poor long-term planning and recovery
In short, real-world tasks are still way more difficult than the manually fabricated ones most RL env companies are building today.

5/
At first, you might think that the minimal post-training improvements are a problem.
But we see some areas of improvement for Gym-Anything that will help accelerate performance.
Simply scaling envs is necessary but insufficient. You need to be scaling specifically high-quality training signal data (with better QA, better verifiers, and better task specification).
6/
The most important piece of this pipeline isn’t the scaling; it’s rigorous QA.
Internally, we’re exploring methods like:
Running the dataset multiple (up to 8) times
Collecting and feeding the trajectories, end state, and verifier outputs back into the model
Ensuring prompts are not underspecified (summarizing and re-feeding the trajectory helps with this)
These techniques have allowed us to identify missed failures and verifier gaps before training runs for envs we’ve shipped to clients.
Also, we should be focusing on tasks that are easy to verify but hard for the agent to do. This materially reduces mistakes that the agent makes.
(7/n)
Gym-Anything gives us a way to generate highly realistic envs and tasks at scale, but this is not enough.
To actually produce large model gains, we need to build a fully self-improving training system (with embedded QA rather than QA afterwards).
That is what produces real hillclimbing (even on long-horizon workflows).
Authors: Pranjal Aggarwal, Graham Neubig, https://x.com/wellecks
