Priorities in LLM-Generated Environments
1/
There are 3 elements to improving models:
Architecture
Compute
Data
No one is changing (1), (2) is actively being solved by the compute giants.
Now what’s left is (3), which has effectively become 2026’s “pickaxes in a gold rush.” Today, the choke point is fully human-created data.
We at Vibrant Labs believe AGI will not be achieved by human data alone, so we’re laser-focused on synthesizing as much as possible to advance models to the next frontier.
2/
Last week in our internal Paper Club, we covered three papers that explore this topic.
Alibaba/Tongyi Lab’s AgentScaler, DeepWisdom/MetaGPT’s AUTOENV, and OMNI all propose methods of using LLMs to synthetically generate environments, tasks, env specifications (harness, etc.) and reward logic.
3/
AgentScaler creates tools, clusters the tools into a dependency graph, then creates scenarios accordingly. Their synthetic env was capable of improving Qwen and other models, but it was still limited to SFT (we’re expanding this to RL runs as well).
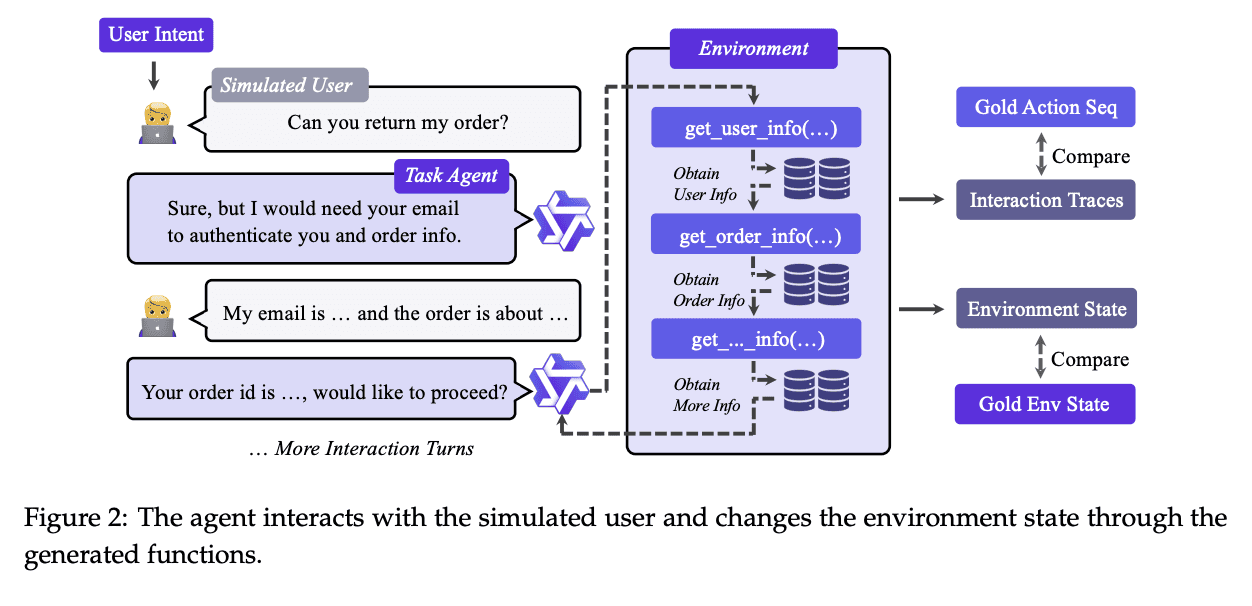
4/
In AUTOENV, the LLM creates a .yaml config then uses it to create action spaces, observation spaces, and rewards in a self-running loop.
Their reliability check method is interesting too - if an older/worse model (ex: Qwen-3.4) consistently has a higher reward score than a newer/better model (ex: GPT-5.4), then they throw out the environment.

5/
OMNI goes further by quantifying how “interesting” (OMNI) and how “learnable” (LP) these tasks are to humans.
For example, a task like “Go to Gmail, star an email, then delete it” is easily learnable and verifiable, but it is not interesting for humans, and should therefore not be included in RL runs.
We plan to do more research on Open-Endedness here as things progress.
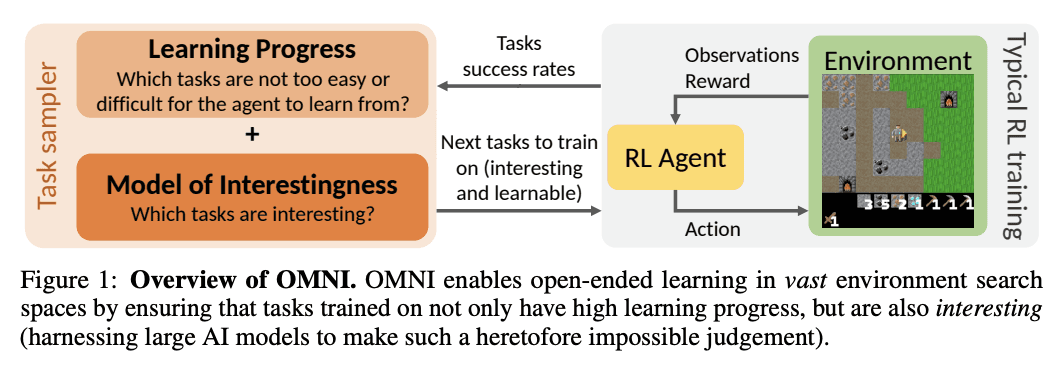
6/
We’re combining some techniques from these studies:
World and scenario generation from AgentScaler
Automatic env design + task and verifier mining from AUTOENV
The notion of human interestingness combined with task learnability from OMNI to sample a subset of all the generated tasks
to properly create synthetic post-training data at scale.
8/ If/when this works, it will dramatically expand the number and diversity of environments frontier models can train inside.
Ultimately, it will help train agents to generalize across many contexts instead of overfitting to a single, limited use case.
Papers:
Authors: Jiayi Zhang, Yiran Peng, Fanqi Kong, Cheng Yang, Yifan Wu, Zhaoyang Yu, Jinyu Xiang, Jianhao Ruan, Jinlin Wang, Maojia Song, HongZhang Liu, Xiangru Tang, Bang Liu, Chenglin Wu, Yuyu Luo
Authors: Runnan Fang, Shihao Cai, Baixuan Li, Jialong Wu, Guangyu Li, Wenbiao Yin, Xinyu Wang, Xiaobin Wang, Liangcai Su, Zhen Zhang, Shibin Wu, Zhengwei Tao, Yong Jiang, Pengjun Xie, Fei Huang, Jingren Zhou
Authors: Jenny Zhang, Joel Lehman, Kenneth Stanley, Jeff Clune
