Generating Effective Learning Environments
1/
We at Vibrant Labs study the literature, old and new, on autoscaling RL environments so we can build better ones.
This week in Paper Club, we went a level deeper: not just what makes a good environment, but what makes a good learning environment, and how to verify that training is working at all.
We covered:
AI-GAs
Agent Psychometrics
The Universal Verifier
2/
Jeff Clune's AI-GAs paper (ahead of its time in 2019, while he was at Uber AI Labs / UWyoming) is one of the foundational pieces on what it actually takes to produce general intelligence automatically.
His argument is that the manual approach to AI (discovering building blocks and engineering them together) is too brittle. The more promising path is an algorithm that learns to generate the conditions for intelligence itself.
The third of his three pillars is what's most relevant to us: automatically generating effective learning environments. It's the least-studied of the three, and arguably the hardest.
3/
The core insight from AI-GAs is that intelligence doesn't require hand-crafted complexity. It emerges from simple rules (e.g., mutation, selection, co-evolution) applied consistently in well-designed environments.
We're doing the same thing, but with LLMs and coding agents instead of evolutionary algorithms. Getting them right is what unlocks everything else.
4/
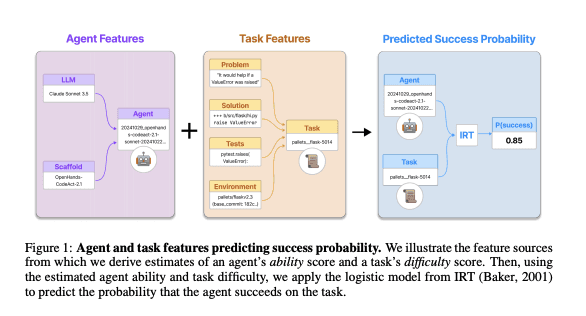
Next up is Agent Psychometrics from the folks at MIT, Fulcrum, and CMU.
The primary question posted here is whether we can if an agent will succeed on a task without running a full rollout?
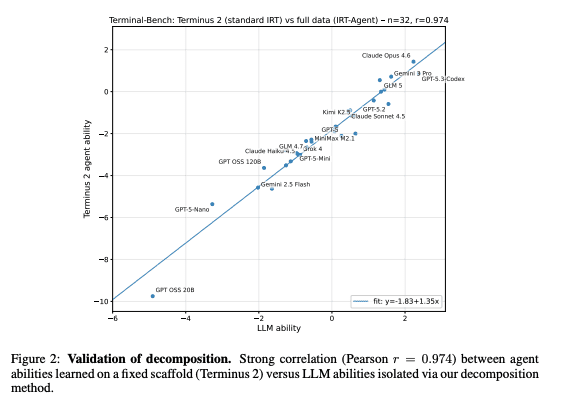
The method involves extending Item Response Theory (essentially the framework behind the SAT) to agentic coding benchmarks. Agent ability is decomposed into two additive components: the underlying LLM and the scaffold (basically the harness). They then predict task difficulty from features like the problem statement, repo state, test patches, and solution patches.
5/
As you might expect, richer agentic features consistently outperform just the problem statement. Generalization is strong for new tasks and new agent combinations but weaker for entirely new benchmarks.
We’ll likely take inspiration from this by running one rollout to calibrate, then using the model to avoid redundant rollouts on expensive runs.
Given what a single run of a frontier model costs at scale, this kind of difficulty prediction could meaningfully cut eval costs.
6/
Last, we covered the Universal Verifier from the folks at Microsoft Research and Browserbase.
Verifying whether a computer use agent actually succeeded is harder than it sounds. Trajectories are long, visually rich, and ambiguous. Getting this wrong corrupts both benchmarks and training signal.
The Universal Verifier is built around 4 principles:
Non-overlapping rubric criteria
Separate process and outcome rewards
Distinguishing controllable vs. uncontrollable failures
Divide-and-conquer screenshot selection to handle long trajectories w/o overwhelming context

7/
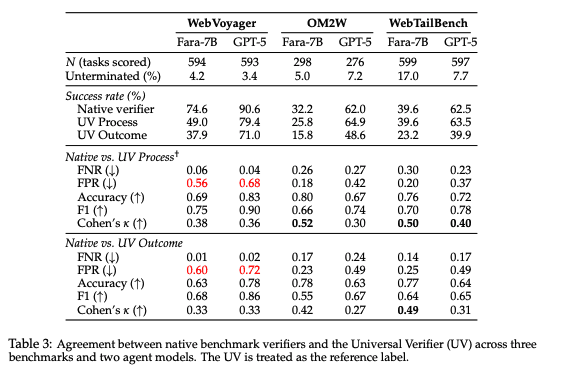
The process/outcome separation stood out to us here.
An agent that navigated correctly to a product that turned out to be out of stock deserves credit for the process even if the outcome failed. Conflating the two either over-penalizes agents for factors outside their control, or lets bad agents off the hook by giving an A for effort.
Separating these items led false positive rates to drop to nearly zero vs. baselines like WebVoyager (≥45%) and WebJudge (≥22%).
8/
All three papers point at the same underlying problem: the quality of the training environment (+ its tasks, its verifiers, and its exploration space) determines the ceiling of what RL training can achieve.
As the Universal Verifier rightly points out, a natural next question from here is whether AI autoresearch agents can replace human annotators in designing verifiers. We’re focused on the same problems. Once the full post-training stack can be handled autonomously, the sky’s the limit.
9/
Author: Jeff Clune
Authors: Chris Ge, Daria Kryvosheieva, Daniel Fried, Uzay Girit, Kaivalya Hariharan
Authors: Corby Rosset, Pratyusha Sharma, Andrew Zhao, Miguel Gonzalez-Fernandez, Ahmed Awadallah
