Failure-driven Task Mining
1/
In the past week, a bunch of people reached out to me wanting to learn more about Tau2-Infinity (our latest benchmark) and the latest Autoscaling RL Environments dinner we hosted in SF.
Every time we at Vibrant Labs preach about synthetic data generation being the biggest bottleneck in AI today, more people join the conversation.
Two counterpoints that are often brought up with autonomously scaling post-training data are:
How do you ensure you’re mining tasks the model genuinely can’t complete?
How do you write verifiers for non-verifiable tasks?
Today, let’s discuss some solutions to these problems.
2/
In last week’s Paper Club, we went deeper into very recently published papers that are focused on these exact topics:
TRACE from the Scaling Intelligence Lab at Stanford
RIFT from Snorkel AI
3/
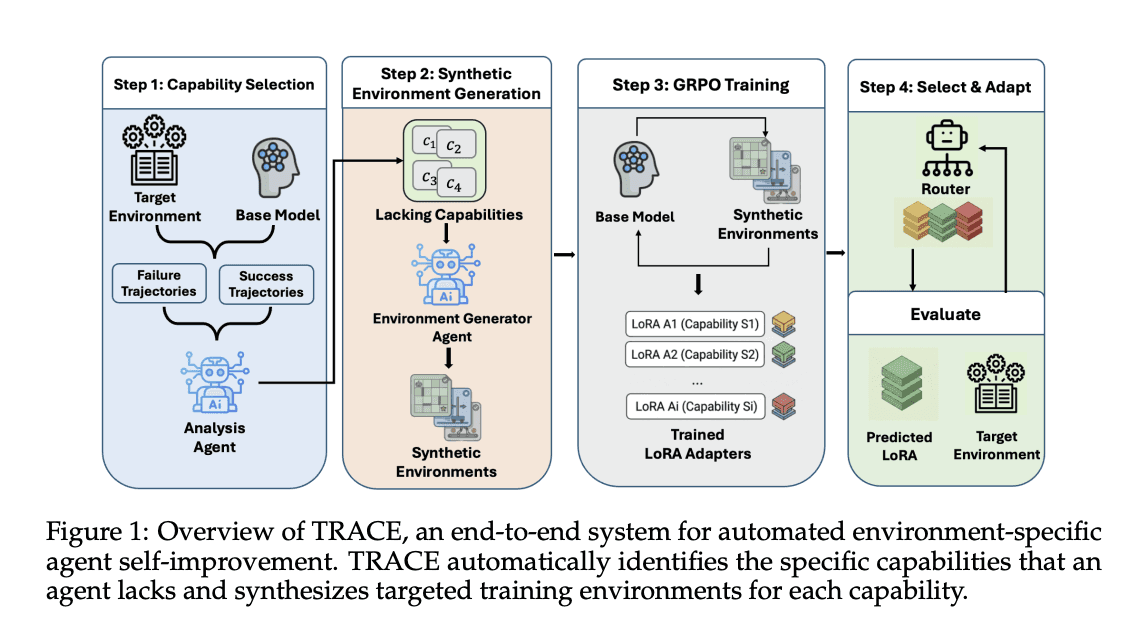
TRACE primarily focuses on capability-based task mining. In TRACE, the team:
Runs a model on a large set of existing tasks
Labels each trajectory with the capabilities it required (using an LLM)
Clusters the capability descriptions into categories (using an LLM), e.g., trajectories defined as “searching for an item” are together
Selects capabilities that show up in 10%+ of failed trajectories
Calculates the “contrastive gap” (measure of how much the capability was missing in failed vs successful trajectories)
The contrastive gap is an improvement over regular error analysis (just looking at failures) since it reduces the number of false positive capabilities.
It also helps distinguish when the issues are due to model capability gaps vs harness/env problems.
TRACE led to significant gains over the base model on benchmarks like Tau2-Bench.
4/
Most suggestions to the non-verifiable task problem involve using an LLM-as-a-judge approach.
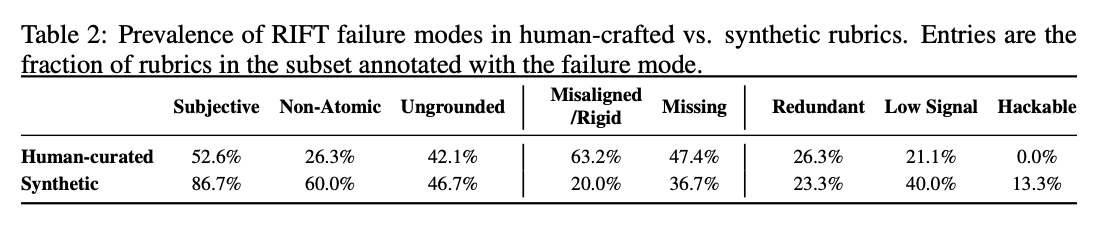
RIFT covers what failure modes are likely to occur with LLM-as-a-judge rubrics, and how to surface them.
In RIFT, you run a loop of the same trajectory through the same rubric n times (”reward variance”) across multiple models (”inter-model agreement”). A low variance and high agreement mean the rubric is good.
Since most realistic envs (especially enterprise) have a mix of write-based tasks and read-based tasks, the reward signal is heavily influenced by the reliability of the rubric.
Some of our upcoming work on Tau2-Infinity is heavily rubric-based, and we’ll reference methods like those shared in RIFT in later announcements.
5/
Employing techniques like TRACE and RIFT will help us scale up our tool-use environments like Tau2-Infinity to be more robust, larger synthetic post-training datasets.
Authors: Hangoo Kang, Tarun Suresh, Jon Saad-Falcon, Azalia Mirhoseini
Authors: Zhengyang Qi, Charles Dickens, Derek Pham, Amanda Dsouza, Armin Parchami, Frederic Sala, Paroma Varma
