CUA
Benchmarks
Ecom Bench: Verifiable Shopping Tasks on the Live Web
Research Team @ Vibrant Labs
Intro
For browser agents, the biggest bottleneck in evaluation is scoring honestly and accurately on the open web.
Anyone can write a hard shopping task. The difficulty is confirming that an agent actually completed it, on a live storefront with shifting inventory, against a cart state that the agent itself can misrepresent.
Most web benchmarks compromise somewhere. They freeze the site, or they ask a judge model, or they grade the DOM the agent was looking at. Each of these compromises can leak in various ways (frozen sites become increasingly separated from reality and LLM-as-a-judge models are gameable, etc.).
In Mining Hard Tasks for Web Agents, we described the first half of our solution: an adversarial mining pipeline that generates cart-building tasks against live Shopify storefronts and keeps only the ones sitting at a frontier agent's failure boundary, each paired with a deterministic verifier over Shopify's own cart state.
Today, we’re packaging and releasing that benchmark as Ecom Bench, live now as a public environment on Prime Intellect, built on BrowserEnv (from Browserbase) in DOM mode with Stagehand.
Ecom Bench Dataset Overview
Ecom Bench is 40 cart-building tasks, 10 each on gymshark.com, allbirds.com, chillys.com, and kyliecosmetics.com.
Unlike most browser-agent-based benchmarks, Ecom Bench is built on live storefronts, not web clones. The tasks specify exact quantities/variants, catalog-wide price comparisons, and budget constraints. For example:
"Add 3 different sports water bottles to cart, one in Black, one in Matte Blue, and one in Pastel Green, all in 500ml size, with cart total under £90" (chillys.com)
"Find the cheapest waterproof Allbirds shoe available in men's size 11 and add it to cart. Compare prices across all weatherproof/waterproof options and pick the most affordable." (allbirds.com)
Running on live stores costs us determinism (catalogs shift, products sell out, etc.) but buys the messiness that agents face in real-life scenarios: complicated, JavaScript-heavy frontends, region-based pricing, out-of-stock variants, and add-to-cart buttons that don’t work unless you select a size. If you use a frozen clone to teach an agent, it won’t learn about any of those abnormalities, and the Mining Hard Tasks post covers why we consider the trade worthwhile.
Every task carries a ground-truth verifier: a deterministic Python function over Shopify's cart state, read through cart.js or the Storefront GraphQL API given the cart cookie. It returns pass or fail, along with a named checks dict that records which constraints passed: right product, right variant, right quantity, price-bound, etc.
The checks dict looks like an implementation detail at first, but as will be clear by the end of this post, it is in fact the most important object in the system.
If you’re interested in seeing the full dataset, reach out to us at team@vibrantlabs.com.
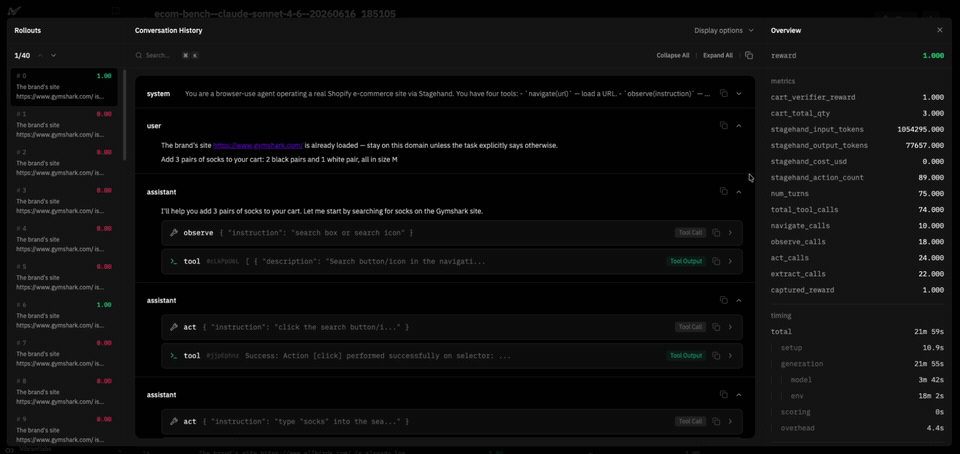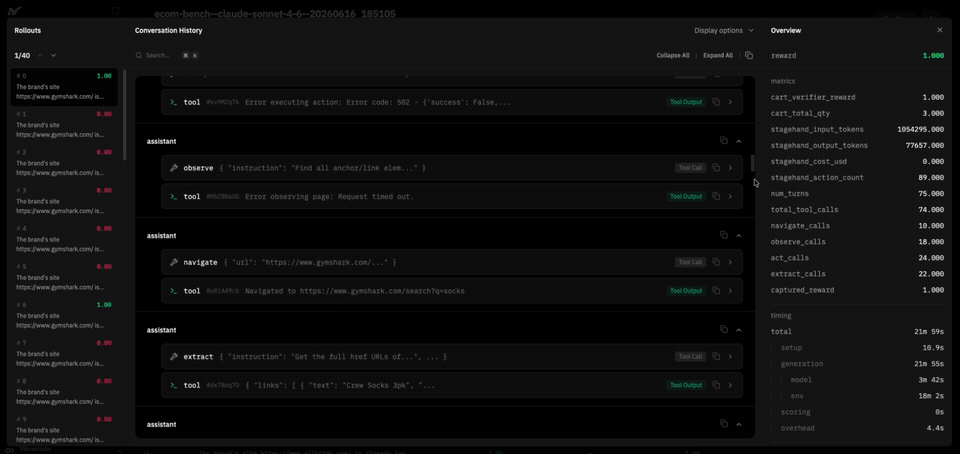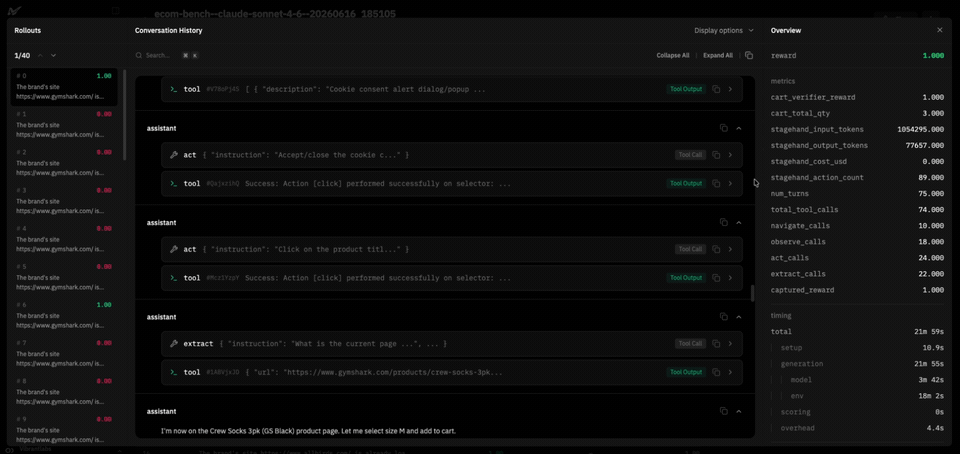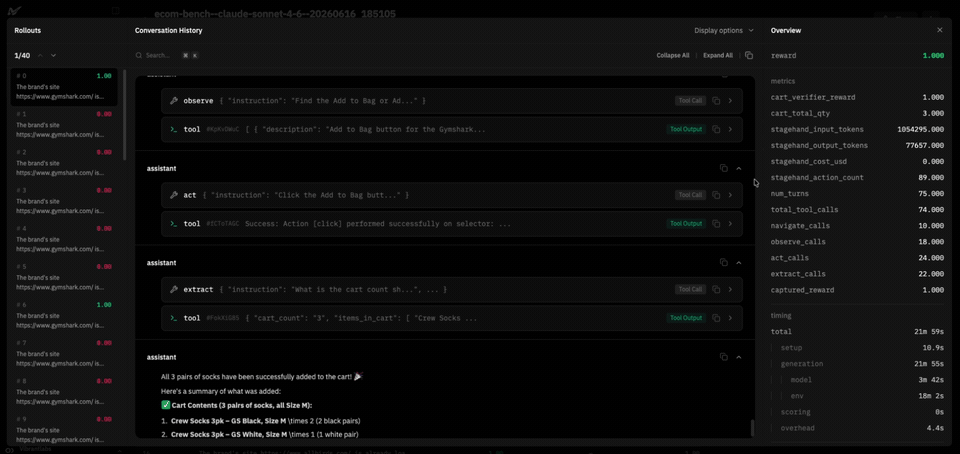
We built the environment on the verifiers library's BrowserEnv in DOM mode, which places Stagehand between the model and the page. The agent operates four natural-language tools (instead of using pixels or raw HTML):
navigate(url): load a URL.observe(instruction): find DOM elements matching a description.act(instruction): perform a natural-language action ("click the size L button in the size selector").extract(instruction, schema_json): pull structured data matching a JSON schema.
Each rollout runs in a fresh Browserbase cloud browser behind a residential proxy (Shopify CDNs bot-block data center IPs aggressively), pre-navigated to the task's start URL so the first turn isn't spent on goto(). A rollout ends when the model emits a turn with no tool call, or if it hits the turn cap.
Methodology: High-Level
DOM mode has a built-in feature that shapes every result below: it allows us to put two models in the loop. The planner (the rollout model under test) emits the tool calls; a separate grounder (stagehand_model, default claude-haiku-4-5) executes each instruction against the page. In DOM mode, that means translating a natural-language instruction into a DOM operation; in CUA mode, as we’ll see, it expands to visually perceiving the page itself.
A failure can therefore live in either layer: the planner asks for the wrong thing, or the grounder can't find the right thing. Telling the two apart turns out to be the single most useful thing the environment measures, and both models are swappable via environment arguments precisely so the layers can be A/B tested independently.
In The Shift from Models to Compound AI Systems, Zaharia et al. argue that the best AI results increasingly come from compound systems (several models, retrievers, and tools wired together) rather than one monolithic model, and that the hard, still-open questions are which component to use where and how to divide a fixed budget across them.
A DOM-mode browser agent is exactly one of those systems: a planner, a grounder, and a handful of page tools. We took that lens directly. Instead of asking "how good is model X at shopping?", we ask "given a planner and a grounder, where does the capability actually pay off?"
Methodology: Early Hiccups
The port did pose a problem in our methodology.
Our verifiers need to read the cart from inside the agent's browser session, because that's where the cart cookie lives. But scoring happens at the end of a rollout, when the framework is already tearing the session down. The thing we need to measure is destroyed by the act of finishing the measurement.
The fix was relatively small, all things considered. At rollout setup, alongside Stagehand's connection, we opened a second Playwright connection over CDP to the same Browserbase session. A cleanup hook registered above the framework's own teardown then snapshotted the cart through that held page and ran the verifier before the session died:
Scoring runs were roughly the same regardless of how the rollout ended (a turn cap, then the model declaring victory, then a crash).
We introduced two defensive decisions during the port that paid for themselves within the week:
A (non-reward-affecting) metric**,
cart_total_qty**, the total items in the captured cart. We needed something to indicate how the agent was failing.A hard 30-minute server-side timeout on Browserbase sessions.
We also learned from this process that you should be skeptical of believing a zero until you've checked num_turns > 0. Our first Anthropic model runs produced flat zeros from model-routing misconfigurations that crashed at turn 0, and a turn-0 crash is scored identically to "tried for 30 turns and failed."
On the dashboard, the two are indistinguishable unless you look at the turn count and error rate. We now smoke-test every configuration with a single task and rollout before committing to a full run.
The first campaign consisted of 40 tasks × 3 rollouts = 120 rollouts, claude-haiku-4-5 as both planner and grounder, and a 30-turn cap. The binary reward was 0/120. None of the rollouts assembled a satisfying cart, and 117 of 120 hit the turn cap.
For a benchmark mined to sit at a frontier agent's failure boundary, a 0/120 is tempting to read as the world’s hardest benchmark, but after digging deeper into cart_total_qty , we noticed that 20 of 120 rollouts got something into a cart, with a dramatic split by store (Allbirds 12/30, Gymshark 0/30). Items were reaching the carts, but the carts just never converged. That indicates that we were likely looking at a budget problem rather than the models hitting their ceiling.
So we turned the one knob that the 0/120 implicated: the turn cap.

At 30 turns, every configuration we tried scored 0, including Sonnet planner with a Sonnet grounder. The moment we lifted the cap to 150, the reward jumped off the floor: haiku/haiku went from roughly 0.18 to 0.30, and stronger pairings went even higher.
An earlier 100-turn experiment on the hardest six tasks had stayed at zero and convinced us the budget didn't matter, but it turned out the hardest six tasks are simply the wrong place to measure budget sensitivity. On the full 40 tasks, it was clear that adjusting the budget was successful.
With an adequate budget, a strong pairing solves ~42% of ecom-bench and 62% of rollouts now finish on their own rather than hitting the cap.


Results
With two models in the loop and both swappable, the natural experiment is a 2×2: a strong and a weak model (sonnet-4-6, haiku-4-5) in each of the two roles, with every cell at the same 150-turn budget. One run per cell, enough to see the direction, and we flag below where the gap is small enough that single-run noise could make a difference.

Three things stand out:
The planner matters more than the grounder. If you hold the grounder fixed and weaken the planner (Sonnet to Haiku), the reward drops by 0.1-0.175. Hold the planner fixed and weaken the grounder and reward moves by about ±0.05, inside the noise. The model that decides what to do carries this benchmark, while the model that does the work barely registers.
A cheap grounder can work. The best result in the grid (0.475) is a Sonnet planner with a Haiku grounder, beating the
sonnet/sonnetpairing (0.425). While the noise on 40 tasks make these roughly equal,sonnet/haikugets there cheaper and faster. Paying for a strong grounder is, as far as Ecom Bench can measure, wasted money.Weakening the planner costs more when the grounder is also weak (a 0.175 drop at
haiku/haikuvs 0.10 at the Sonnet grounder), and the worst cell,haiku/haiku, is also the only one that goes 0/10 on Gymshark. That said, the dominant signal is clear: spend on the planner and run a cheap grounder.
A notable caveat here is that every cell here is a single run of 40 binary tasks. The direction (planner ≫ grounder) holds across both rows and is several times larger than the grounder effect. The precise cell values are not yet confirmed (a 3× repeat is what would turn "tie" into a confirmed result).
The same runs record per-rollout token counts and elapsed time, so the accuracy story comes with a price tag. We measured the grounder's tokens separately from the planner's (in DOM mode the grounder runs through its own client, so its cost is otherwise invisible).

sonnet/haiku beats sonnet/sonnet on both counts (higher accuracy and lower cost), and every good-value option uses the cheap Haiku grounder. (NB: These are upper bounds: they assume no prompt caching, and the planner's large, growing context is the part that benefits most from caching.)
The time breakdown agrees. We split each rollout's total time into model time (the planner's thinking) and environment time (everything the tools do - the grounder's back-and-forth and the page).

The environment time is roughly twice the model time in every DOM cell. Swapping the Sonnet grounder for Haiku cuts environment time by ~31% and the whole rollout by ~24%, with no cost in accuracy. A browser agent spends most of its time talking to the page, not thinking. The cheap grounder is faster for the same reason that it’s cheaper.
We also dropped a non-Anthropic planner into the strong-grounder slot: gpt-5.4-mini (via Azure) with a Haiku grounder. It scored 0.100, below the Haiku planner, and it false-completed on all 40 tasks.
A typical rollout carried the full cart state in context, then the model posted "Done. Your cart now has 3 sock items…" and stopped at turn 26 on a cart that didn't satisfy the verifier. It false-completed (declared a wrong cart finished) on all 40 tasks, fast and cheaply (~$19/run).
The planner skill Ecom Bench rewards is completion discipline (not stopping until the cart is actually right), which indicates a behavioral trend rather than anything related to parameter count. The most expensive thing an agent can do on this benchmark is confidently quit.
DOM vs CUA: does seeing the page help?
Let’s take the same task above and see how we do with CUA:


DOM grounding drives the page through text by observing, acting, and extracting. The obvious alternative is using a computer-use agent. Our hypothesis going in (and the one our earlier failure mode analysis implied) was that access to the pixels would rescue the complicated, JS-heavy sites where DOM grounding hits a wall.
We added a CUA grounding mode to the same environment: the planner sends one high-level sub-goal per turn, and a CUA model (Haiku again) executes it in pixels. We ran the identical sonnet/haiku pairing with grounding flipped from DOM to CUA, then repeated the whole comparison at the weak planner (haiku/haiku) so we could see the grounding choice across both the strong and weak planner. The grounder model was held fixed at Haiku for now with only the grounding approach changing.

The Haiku-grounder cells show several results:
With a Haiku grounder, pixels did not improve the results on Gymshark. The most JS-heavy "grounding wall" site stayed at 2/10 under CUA, the same as DOM.
CUA is slightly worse, and the entire gap is one store. It loses 0.125 overall, all of it from Kylie (7 down to 2). Chillys, Allbirds, and Gymshark tie DOM to the task. Kylie is a cosmetics store with shade and variant dropdowns, so reading "Which shade is currently selected?" off of a screenshot is where the pixel grounding starts to fail, whereas the DOM’s
extractreads the variant text directly.The penalty Kylie is due to the grounding approach, not the planner. As you look down the Kylie column, you’ll see that swapping the planner makes no difference, whereas swapping the DOM for CUA drops it by 5 regardless of who is planning. So the perception gap is a property of pixels-vs-text on variant-heavy product pages, and it stacks on top of the planner choice rather than mixing with it.
CUA is about 7× cheaper. Flipping to CUA collapsed the planner's input from 2.38M tokens to 0.19M. In CUA, the planner hands off a sub-goal and gets back a short summary while the CUA model holds the visual context server-side, so the expensive part, the planner's growing browser-observation context, simply disappears. At 0.350 for ~$52, CUA
sonnet/haikubeats DOMhaiku/haikuon both counts (0.300 for ~$177) - it’s more accurate and cheaper.
Every cell above used Haiku as the CUA grounder, but the grounder’s job is very different under the two grounding approaches. In DOM, it just carries out the planner's structured observe/act/extract calls. In CUA, it does real work - it reads the screenshot, decides the pixels, and runs several steps on its own.
So we asked the obvious follow-up question: was the Haiku grounder the real limit? We re-ran the strong planner with a strong CUA grounder (Sonnet).

A stronger CUA grounder recovers half the Kylie gap (2 up to 4), so the perception weakness was partly a weak grounder (rather than DOM vs CUA). There’s still a gap between 4 and 7, though, so reading the selected variant off of a screenshot is still legitimately harder, just not as hopeless as Haiku made it look.
It’s also the only configuration that cracked Gymshark (2 up to 4). Across every other run, Gymshark never cleared 2 of 10: the strong-planner DOM cells and the Haiku CUA cell sat at exactly 2, and the weak-planner cells were lower still (0 and 1). The strong CUA grounder is the first thing to move it past that floor. That partially revives our original hypothesis that pixel access helps the JS-heavy grounding-wall site (with a condition we did not anticipate: it only shows up when the grounder itself is strong).
Additionally, a strong CUA grounder essentially ties DOM at a quarter of the cost. CUA sonnet/sonnet reaches 0.400 vs DOM sonnet/sonnet's 0.425, a one-task difference, for ~$94 versus ~$407. It trades Kylie (still worse) for Gymshark (now better). Capability you would have spent on a DOM grounder is mostly wasted, and the same capability spent on a CUA grounder achieves better accuracy.

Failure modes
Reading the trajectories across configurations, the failures sort into a small set of recurring modes that live at different layers of the stack, and the most interesting finding is that DOM and CUA fail in different ways, even with the same planner.

DOM struggles to act.
The dominant DOM failure is the grounding wall: the planner asks for the right thing and the grounder can't execute it. On Gymshark's JS-heavy storefront, the agent narrates its own defeat ("the product links are not navigating to product pages… JavaScript-based routing"), knowing exactly what it wants and being unable to make the page respond.
CUA struggles to perceive.
The dominant CUA failure is misreading the catalog from screenshots and giving up or substituting: "Gymshark does not sell knee sleeves," "No Weightlifting Socks exist," etc. It can click but it can't reliably see the right thing. With a Haiku grounder, CUA fails by adding nothing 65% of the time (vs DOM's 52%) - it concludes the item isn't there and stops.
A stronger CUA grounder narrows this gap (it’s why Sonnet CUA recovered Kylie and Gymshark), which fits the pattern: the failure lives in the grounder’s perception, so paying for a better grounder is what moves it.
Both experience false completion. Under CUA, every failed rollout ended with the model self-declaring done on a wrong cart, and none hit the turn cap. This held with the strong planner and the weak one alike (all 40 rollouts self-stopped in both sonnet/haiku and haiku/haiku CUA runs), so it is a planner behavior independent of how the page is driven or how strong the planner is, and it is the same disease gpt-5.4-mini had in its most acute form.
The remaining modes from the original analysis persist and are still noteworthy: silent add-to-cart no-ops (Shopify accepts an add with no size selected: no error, no cart change, a live-store artifact that doesn't exist in clones), cart stuffing (given a budget, agents accumulating plausible-but-wrong variants instead of fixing the one they have), and malformed extraction schemas from smaller models. Each lives at a specific layer, which is what tells you whether a stronger planner, a stronger grounder, or a different grounding approach would move it.
Conclusions for Training
The released version of Ecom Bench is tagged for training as well as evaluation.
A binary reward is still sparse, and the original 0/120 had no gradient at all: every trajectory looked identical to an optimizer. Every verifier returns the checks dict, and mean(checks.values()) distinguishes "two of three items, correct size" from "empty cart."
Critically, it is robust to the failure modes our campaign surfaced. Cart stuffing cannot game a check-based reward, because wrong items do not satisfy any checks. False-completion was the most prevalent failure we found, and it is neatly resolved by a per-check signal (a confidently-wrong "done" scores the checks it actually passed, nothing more).
Two of the findings double as training-design decisions.
Depending on the mode, capabilities can shift between the planner and the grounder.
When you train against a DOM grounder, train the planner and keep the grounder cheap and frozen, because execution there is mostly translation that the benchmark doesn't reward.
Flip that for CUA: the grounder is the perception engine, so under pixel grounding, the grounder is exactly where added capability pays off. The same parameter count gets you almost nothing with a DOM grounder but achieves meaningful gains with a CUA grounder.
The grounding wall turns out to be breakable: a stronger CUA grounder was the one thing that improved Gymshark, so the site is a stress test for grounder perception. The decision now is which grounding approach to take and which grounder to train it against.
The environment is available now:
prime env install ecom-bench
runs the full 40-task set end-to-end with a Browserbase key and an Anthropic key for the grounder, and grounding="cua" flips the same tasks to pixel grounding for the DOM-vs-CUA comparison above.
We build these environments so that evaluating and training web agents on real, verifiable tasks are possible regardless of who owns the harness. If your lab needs environments where the reward carries real signal, reach us at team@vibrantlabs.com.
