Tool-Use
Data
LLM
Tau2-Infinity: Autonomously Mining Hard Tasks for Tool-Use Agents
Research Team @ Vibrant Labs
May 12, 2026
Intro
The bottleneck for building better tool-use agents is not algorithm design; it’s post-training data quality and quantity.
Specifically, it’s the supply of perfectly hard tasks: tasks that a target model fails on often enough to learn from, but not so often that it’s unable to draw a learning signal. For GRPO and other RL methods, this translates to tasks that fall within a desired pass@k window, where variance is high enough to produce signal on every rollout.
Human-curated benchmarks for tool-use don’t supply this level of granularity for tasks.
For example, Tau2-Bench is a significant achievement in evaluating frontier models on enterprise-level customer support tasks, but when labs train their models on benchmarks like this, they often saturate quickly.
The industry’s response has mostly been to scale human annotation, but once you want to mine tasks tailored to a specific model’s failure modes, human-in-the-loop quickly becomes human-in-the-way.
We’ve been working on an alternative solution: Tau2-Infinity, which incorporates synthetic task mining that runs in a loop against a target model, harvests tasks at the edge of its current capability, and produces those tasks, verifiers, and surrounding environments.
Below, we cover two approaches to solving this problem:
Tau2-Infinity-DAG: an tool-graph-based approach that samples a valid tool DAG first, then builds a task and env around it, which guarantees that the task is solvable.
Tau2-Infinity-WG: an oracle-model-based approach that formulates a failure mode hypothesis based on past eval history, generates worlds to test them, then uses an oracle to filter out unsolvable scenarios.
Approach 1: Tau2-Infinity-DAG
We start with identifying an existing human-curated benchmark with a given scope like Tau2-Bench where we want to improve a target model M. Today, most of the SOTA models have already saturated on publicly available Tau2 data.
Our aim is to find valuable failure modes in which SOTA models fail in the given domain/scope and to synthesize tasks, environment, and verifiers targeted to improve the models on those failure modes and tasks.
Preliminary Step
For this, we start with a parameter space that is derived from existing tasks in the benchmark (for Tau2, these are user_intents like booking, cancellation, updating, etc., number_of_bags, num_actions, etc.).
We then build a dependency graph on existing tools in the environment. This tool dependency graph forms a directed acyclic graph (DAG) of tools in the given environment.
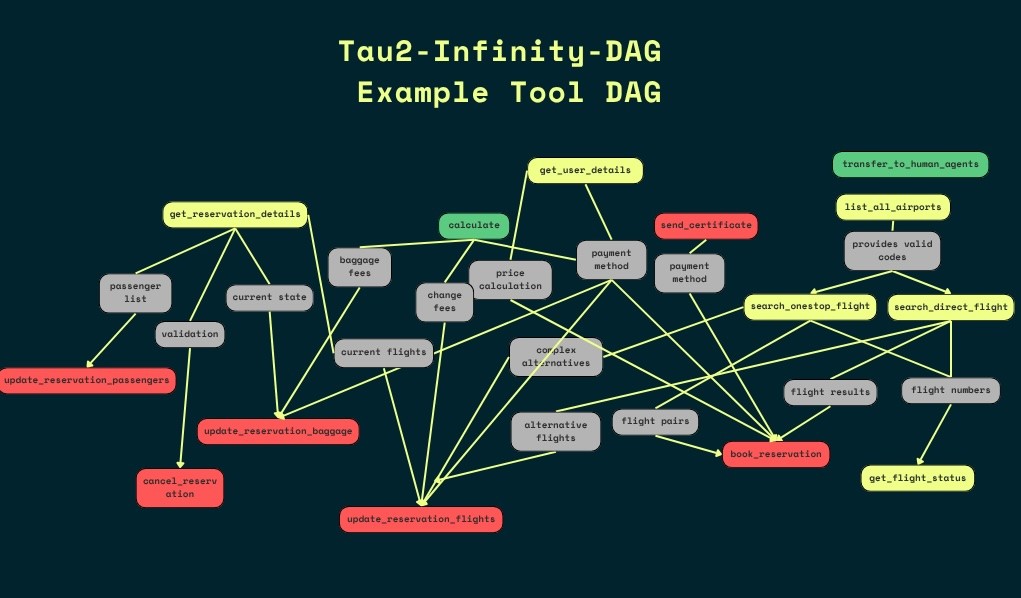
Example Tool DAG used in Tau2-Infinity-DAG
The core iteration loop
Param Proposer: this proposes the next parameter combination to evaluate the model on based on evaluation history. On a cold start, it tries B (batch size) parameter combinations, prioritizing diversity.
Tool Sequence Sampler: this samples a random walk from the tool DAG conditioned on the proposed parameters for each sample in the batch. The sample acts as the ground-truth tool sequence / oracle trajectory for the task to be formed, since the walk can, in theory, be completed in reality.
Environment Synthesis: given the ground-truth tool sequence and parameter combination, an environment (in this case, a database populated with coherent data) is created to support the oracle trajectory. Controlled distractor values are then added to the environment to improve the task difficulty. For example, the distractor might add flight values that fall within the target search radius and could feasibly be booked to confuse the model.
Natural Language Task Formation: given the tool sequence and environment, the natural language task description is formed and validated.
Evaluator: pass@k evaluation is performed on the task. The evaluator also combines the environments, and verifies this process by matching the final state of the model with the expected state using the oracle trajectory on the environment.
Analysis agent: the agent inspects the trajectories and final states from each rollout and compares them with the oracle trajectory and expected final state. It then identifies failure modes (if any failed runs exists), and notes down observations.
The tasks that have a pass rate ≤ target pass rate are selected as valid tasks. The loop runs until we harvest N tasks under required pass rate for the target model.

Tau2-Infinity-DAG Workflow
Failure Modes
Kimi k2.5 primarily ran into difficulties with tasks involving multiple payment methods, confusion between economy and basic economy bookings, round-trip bookings, 3+ passengers, and navigating the baggage policy for basic economy tickets.
With Qwen, a dual booking strategy (comparing both the cheapest flights and the shortest duration flights) led to genuine reasoning failures in flight selection. Increasing to 3 passengers or increasing to multiple intents in the same task (e.g., booking a flight, then updating the number of passengers - especially when one of these involves cancellation) pushes the difficulty reliably below 0.3. Qwen's dominant failure modes were skipping get_user_details, fabricating payment IDs, and miscomputing the flight duration/cost comparisons.
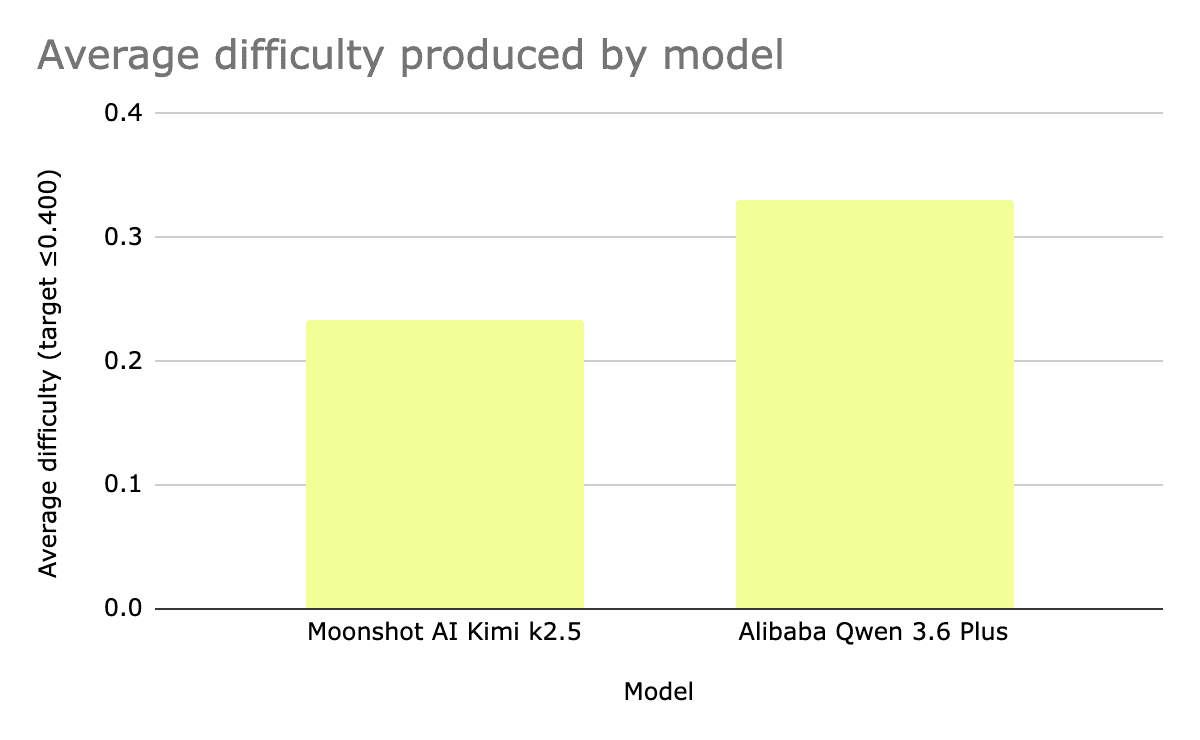
Comparison of task difficulty produced by each model
Using this approach, we harvested tasks for SOTA models. We have released samples for Qwen 3.6+ and Kimi k2.5 with pass rate of ≤ 0.33.
The models tested took a similar quantity of iterations to harvest the 10 tasks (24 for Qwen, 25 for Kimi), and the average difficulty of the tasks collected by Qwen 3.6 Plus was higher than those collected by Kimi k2.5.
Approach 2: Tau2-Infinity-WG
The Search Space
Tau2-Infinity-DAG searches a structured space: parameter combinations (user intent, number of bags, number of actions, etc.) crossed with random walks on the environment's tool DAG. Each sample point is a tuple of pre-enumerated axes plus a valid trajectory. Tau2-Infinity-WG searches an open space composed of natural-language hypotheses that the adversarial agent writes about for where the target will fail. The axes aren't enumerable in advance; the strategist writes them as it goes. Both loops are adversarial. Evaluation history steers the Param Proposer toward hard parameter regions in Tau2-Infinity-DAG, and steers the strategist toward unproven hypotheses in WG.
The Oracle
In Tau2-Infinity-DAG, the oracle trajectory comes first: a valid walk is sampled, then the environment and task are built around it, so tasks are known-solvable by construction. In Tau2-Infinity-WG, the oracle runs last, and only if the target has failed, to check whether that failure points at a real capability gap or a broken scenario. Tau2-Infinity-DAG's guarantee is tighter but its search is bounded by what the tool DAG permits. WG runs some target evals that get thrown away, but the search space isn't constrained up front.
The loop

The system has two levels: a Strategist that reasons over the capability frontier as a whole, and Workers that probe one hypothesis at a time:
1. Strategist (hypothesis formulation): The strategist reads the session summary + frontier map and formulates a natural-language hypothesis about what the target model can handle. Examples of live hypotheses from our runs:
"The model can handle multi-step rebooking when baggage policy applies."
"The model correctly refuses mutations on reservations owned by other customers."
"The model communicates cost breakdowns before executing cabin upgrades."
The strategist's job is to disprove these. Each iteration it picks the next hypothesis to attack, either narrowing in on a boundary it has already found or exploring a region the frontier map hasn't touched.
2. Worker (scenario design and world generation): A dispatched worker takes the hypothesis and writes a world-description prompt in natural language: which entities must exist, how they relate, which properties matter for the scenario to be probing without being unsolvable. An LLM-driven world-actor generates a concrete database state from that prompt. The world is authored from an open description rather than sampled forward from a tool DAG, which is the structural contrast with oracle-forward mining.
3. Target run: The worker runs the target model against the generated world and task. If the target passes, the trial is logged and the worker moves on; that counts as evidence the hypothesis may hold at this complexity.
4. Oracle (as a validation filter) If the target fails, the worker runs an oracle model (default: Claude Opus) on the same task. Two cases:
Oracle passes → confirmed failure. The task is real: the target fails at something a stronger model can solve.
Oracle fails → discarded. The task may be broken: ambiguous, under-specified, or world-gen produced something unsolvable. We don't keep it.
This inverts the oracle's role compared to oracle-forward mining, where the oracle trajectory exists before the task and defines what success looks like. In WG, the oracle runs afterward as a sanity check, filtering out world-gen artifacts that aren't really solvable.
5. Simplification to minimum viable failure: Once a failure is confirmed, the worker generates simpler variants of the scenario and retests. The goal is the smallest scenario that still breaks the target: fewer passengers, fewer intents, shorter policy chains, less distractor content. Without this step, failures stay buried under whatever complexity produced them, and the training signal gets diluted.
6. Frontier map update: Confirmed failures, confirmed holds, and disproved hypotheses all feed back into the frontier map. The strategist uses this to avoid redundant work and to pick hypotheses at the edges of what's been tested.
Tau2-Infinity-DAG vs Tau2-Infinity-WG
The two methods we’ve explored so far differ in the following ways:
Search space: Tau2-Infinity-DAG searches from a structured space (walks across a tool DAG). Tau2-Infinity-WG searches on an open natural-language space - the Strategist invents new axes as it continues its runs. The structured space is easier to reason about and easier to debug, while the open space can reach more unanticipated failure modes
Oracle purpose/timing: In Tau2-Infinity-DAG, the oracle trajectory exists before the task and provides deterministic verification for the task. In Tau2-Infinity-WG, the oracle runs after a failure and acts as a filter to identify real gaps vs broken scenarios. The prior-oracle does not waste tokens on unsolvable scenarios, while the post-oracle allows for greater creativity and diversity in scenario generation.
Failure simplification: Tau2-Infinity-DAG’s complexity is directly derived from the initial parameters, so failures are mostly clean. Tau2-Infinity-WG’s worlds come from LLM-generated natural language, so failures contain potentially confounding complexity, and therefore requires a dedicated simplify-to-minimum-viable-failure step to isolate the real capability gaps.
Surprisingly, both methods also hit similar distribution collapses. Tau2-Infinity-DAG collapsed across parameter axes (like locations or user IDs), whereas Tau2-Infinity-WG collapsed across hypothesis axes (the Strategist kept mining variants of productive veins). It seems that this type of collapse is not a result of a specific search structure.
Building in additional and explicit diversity while closing the loop from training results back into mining will help ensure that the process is focused on harvesting tasks that are teachable, and not just difficult.
Limitations
We ran into several limitations with our approaches here:
Hypothesis-space mining has its own distribution collapse. Tau2-Infinity-DAG reported collapse along parameter-space axes (user_ids, locations) and along early-identified failure modes. We saw the same shape in hypothesis space: once the strategist found a productive vein (e.g. multi-intent reservations), it kept mining variants of that hypothesis instead of exploring orthogonal capability axes. Both approaches converge on the same failure because the collapse comes from the adaptive loop itself, regardless of whether the loop runs over parameters or hypotheses.
LLM-generated worlds sometimes aren't solvable. The oracle-filter catches these, but they're wasted target runs. Tighter world-generation prompts and post-generation consistency checks would cut the waste.
World complexity and realism are still limited. Without real-world noise and richer world dynamics, the behaviors the model learns on harvested tasks may not transfer reliably to real deployments; some failure modes (and improvements) may only appear once we introduce noisier, more sophisticated world generation.
Hypothesis quality depends on the strategist. Shallow hypotheses ("the model can book flights") produce shallow probes. Sharp hypotheses ("the model correctly refuses cabin changes on basic-economy reservations citing the specific policy clause") produce tasks that stress-test a named behavior. Getting the strategist prompt right matters a lot.
Transfer-to-human is a risk-free exit. The compliance penalty only fires on active violations: unauthorized mutations, parallel tool calls. A transfer earns no outcome reward, but it also triggers no compliance penalty. On any borderline task, the rational move is to transfer — a guaranteed zero beats gambling on a potentially compliance-penalized outcome. There's a reward lever for punishing a wrong attempt but none for punishing an unnecessary transfer, so the policy drifts toward transfer as its default safety valve whenever the task signal is ambiguous.
Releases
Tau2-Infinity-DAG
HuggingFace dataset: https://huggingface.co/datasets/vibrantlabsai/tau2-infinity-dag
Prime Intellect environment: https://app.primeintellect.ai/dashboard/environments/vibrantlabsai/tau2_infinity
Tau2-Infinity-WG
HuggingFace dataset: https://huggingface.co/datasets/vibrantlabsai/tau2-infinity-wg
Prime Intellect environment: https://app.primeintellect.ai/dashboard/environments/vibrantlabsai/tau2_infinity_wg
Future Work
We’ll keep shipping improvements to both pipelines publicly. Our broader goal is to generate scalable methods for task/environment creation for use cases like enterprise tool-use, so that the next generation of agents isn’t gatekept by how fast humans can write benchmarks.
