CUA
Benchmarks
Mining Hard Tasks for Web Agents: An Adversarial E-Commerce Benchmark
Research Team @ Vibrant Labs
Intro
Today, many frontier model capability improvements come from agent gyms, not text corpora. As models grow more capable, operate in more complex real-world domains, and take on longer-horizon tasks, gym supply has become the biggest bottleneck. Autoscaling that supply is what we work on at Vibrant Labs.
Over the past few months, we ran a pilot with Yutori and built an autoscaling pipeline that generates training data for n1.5, the latest iteration of their CUA model.
It's important to note that web-agent benchmarks rot quickly. Once a model has trained near WebArena, Mind2Web, etc., the pass rate plateaus and the benchmark stops discriminating. Verifiers built fast get gamed by capable models. Pass/fail tells you the agent failed without telling you what capability it lacked.
What we wanted was the opposite: a continuously refreshed pool of tasks calibrated to the failure boundary of the model under test, on real e-commerce sites, with programmatic verification that doesn't drift when the storefront does.
Concretely: we were seeking tasks where yutori/n1-latest (or, in theory, whichever CUA model we're evaluating) fails on at least 1 of every 5 runs. Not 0/5 (impossible — no learning signal for GRPO), not 5/5 (saturated — no learning signal). The sweet spot is narrow, and most of the engineering goes into staying inside it.
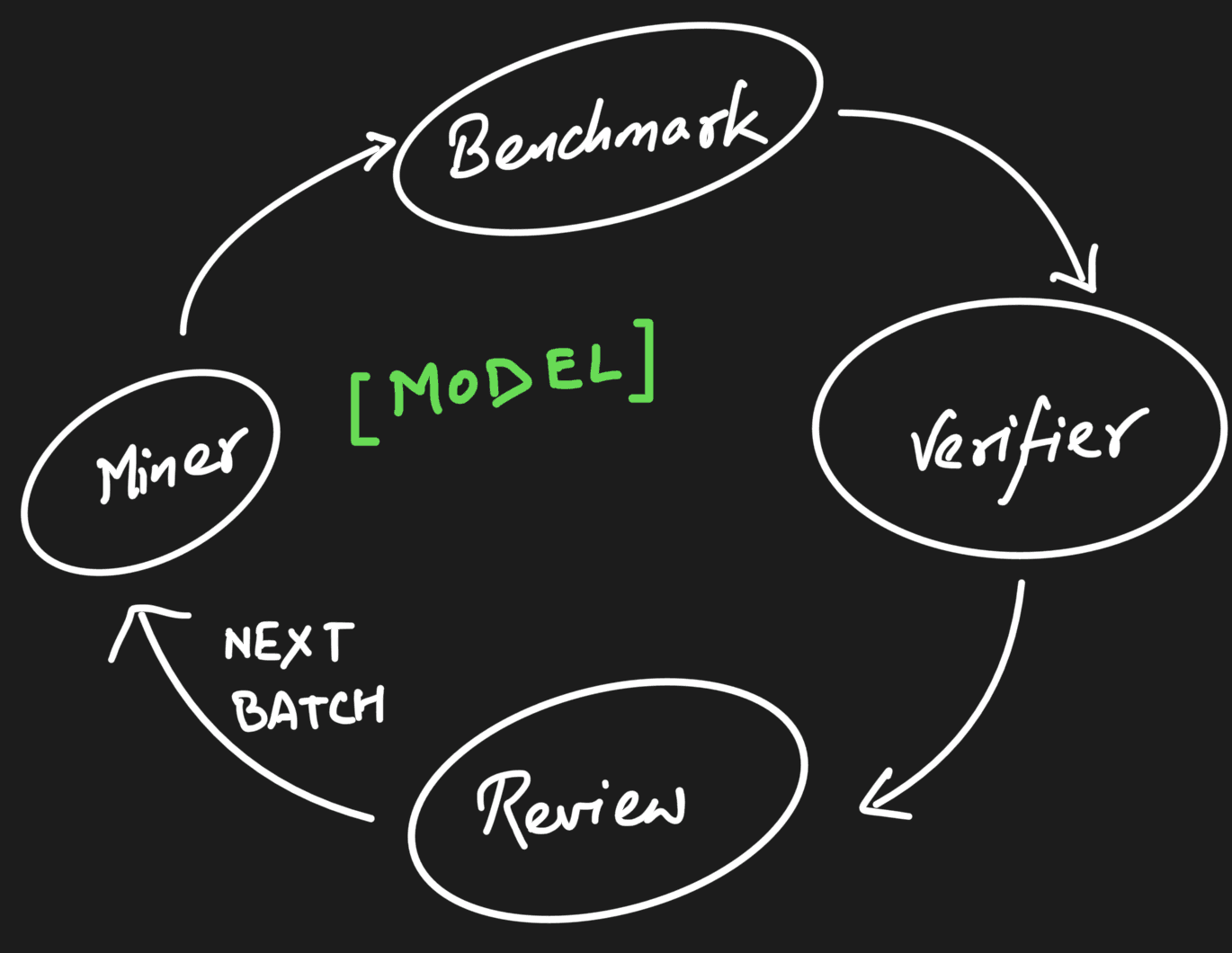
High-level overview of our pipeline
Background: Unsupervised Environment Design and Task Miners
The first idea we borrowed comes from Unsupervised Environment Design (UED), a sub-field of RL that has been formalizing the autoscaling problem for the last five years. Rather than hand-designing environments or randomizing domains, UED learns to generate environments calibrated to the agent's frontier of learnability. The lineage runs from PAIRED (Dennis et al., 2020) through PLR (Jiang et al., 2021), ACCEL (Parker-Holder et al., 2022), and the open-ended POET (Wang, Lehman, Clune et al., 2020). Wins have been concentrated in gridworlds and robotics; translating UED to LLMs is still nascent (Rainbow Teaming, EVA, OMNI-EPIC are early), but the formalism is precisely what autoscaling agent gyms requires.
PAIRED (Dennis et al., NeurIPS 2020) frames curriculum learning as a three-player game between a protagonist (the agent we want to train), an antagonist (a second learner allied with the adversary), and an adversary that proposes environments. The adversary is rewarded for regret, defined precisely as the gap between the antagonist's reward and the protagonist's reward on the same environment:
The gap between the two rewards is the regret — the adversary tries to maximize the regret, while the protagonist competes to minimize it.
Maximizing regret pushes the adversary toward environments that are feasible (the antagonist can solve them, so reward is non-zero) but hard for the protagonist specifically (the gap is large). PAIRED's regret signal sits exactly on the feasibility frontier.
Methodology
PAIRED's adversary is a learned RL policy, trained under regret. Gradient updates push it toward environments that maximize the protagonist–antagonist gap. That setup needs a second RL loop, paired infrastructure, and stable joint training across three networks. We don't have any of that.
Our adversary is a Claude-Code-based task miner running against live Shopify storefronts. There's no adversary policy to train. Instead, we engineer three structural advantages over the protagonist. The miner's leverage comes from these, not from a learned policy.
Tool-use asymmetry: The miner queries Shopify's Storefront GraphQL directly: cart contents, product inventory, pricing, prior session state. It also runs Python over normalized cart snapshots. The protagonist (
yutori/n1-latest) sees a rendered page through a CUA harness. The miner has the data model and the protagonist has pixels.Harness improvements. Following Meta-Harness (Lee et al., 2026), the miner's harness itself is the optimization target, improved iteratively against execution traces of its own past attempts. Skills get added, tool patterns refined, retrieval strategies tuned. Each iteration mines harder tasks than the previous one. This substitutes for training a new adversary policy and gives a PAIRED-style improvement loop without the policy gradient.
Capability-gap analysis. Following Stanford's TRACE (Kang, Suresh et al., 2026), a separate pass analyzes the protagonist's recent failures and identifies which underlying capabilities are weakest. The miner is pointed at those specific capabilities next, rather than mining at random near the failure boundary.
In PAIRED, the adversary's leverage is trained. In ours, it's engineered. Different mechanisms that achieve the same structural goal: an adversary that finds hard tasks faster than random.
Designing the Miner Factory
In practice, that asymmetry is a small set of tools the miner has and the protagonist doesn't, including a memory of every prior session on this site, which is what lets it skip combinations that are obviously easy or already tried. Helix is our internal codename for the platform that facilitates the task/verifier auto-generation process.
Tools we gave the miner
fetch_catalog: refreshes a structuredcatalog.jsonfrom the Storefront API before every session. The miner uses it to construct constraints that are guaranteed satisfiable (the variant exists, the price is real) but not obviously easy: multi-constraint conjunctions, similar-named variants, cheapest-of-type queries that force a comparison.Helix observations API: every prior session's findings plus the accept/reject trail with reviewer comments. New sessions start by reading this. Mistakes don't repeat across sessions.
Research log: freeform
research/{site}/research_log_*.mdlogs the miner appends to during a session. This captures things that don't fit the structured schema (e.g., "this site's size dropdown lazy-loads after 500ms, which trips the protagonist's element resolver"; "Quick Add on collection pages is a different component than on PDPs", etc.). The next session reads these as context./create-verifiersand/evaluate-verifier: covered below.
The Mining Loop

Adversarial Mining Loop
The miner is Claude Code running in a tmux session on an EC2 host, kicked off from the operator's laptop with miner create --site allbirds --target 10. It reads the prompt skill, the research log, and the observation history; proposes a plan; waits once for operator approval; then runs the following steps autonomously:
Generate ≥ max(8, target) candidates against the catalog.
Run them through the benchmark with
-with-classify --with-llm-judge --auto-fail, which spawns its ownbench-*tmux session and respects the Browserbase 100-session cap.Keep tasks whose pass rate lands in the GRPO sweet spot.
Write verifiers, replay one passing trace to confirm them, then push survivors to
ready_for_review.Sleep on
miner feedbackuntil the operator finishes review, then read the trail and start the next batch.
Building, Layer by Layer
We didn't draw the architecture and then go build it. We built the remote runner first, used it initially, and the miner came out of realizing what the runner had quietly become a foundation for. The shape followed what kept hurting.
Stage 1: The Remote Runner. The original pain was simple: closing the laptop killed a run. uv run remote run-benchmark is the minimal version: rsync the repo to EC2, kick off a tmux session, poll for completion, rsync results back. In this process, we commonly observed zombie panes: a benchmark that crashed mid-run left a dead tmux session that the next run collided with. Clean-up-on-start fixed it.
Stage 2: The Miner on Top. The miner is Claude Code, running inside tmux on EC2, doing what we'd been doing manually. The first version did the whole loop in one shot: it read the prompt, generated the candidates and benchmark, wrote verifiers, and submitted. It would also confidently propose 50 candidates on batch one and burn through its Browserbase budget in 20 minutes. We added a plan-then-execute split: the miner starts in --permission-mode plan, reads the observations and research log, proposes a plan, and then waits for the operator to approve it once. After approval, it goes autonomous.
We also got batch sizing wrong at first. Early miners generated exact target candidates, but most would get rejected at review or wash out as too easy in the benchmark, and the next batch had to start over. max(8, target) over-supplies on purpose.
Stage 3: Closing the Feedback Loop. This is where most of the iteration time was spent. "Operator reviews → miner reads feedback → next batch incorporates it" sounds obvious, but the first version didn't work properly for about a week and a half. We ran into the following issues:
Reviewer comments lived only in Slack. The miner never saw them → We moved the comments into Helix's task and batch records
The miner polled Helix every 60 seconds while waiting. Four parallel miners checking Helix repeatedly led to us rate-limiting ourselves → We reversed the mechanism such that any new task reviews were pushed proactively to the miner, thereby reducing cost.
The miner read accepted comments but ignored rejected-task ones, on the theory that rejections were just noise. They weren't — the reasons for rejection were the most useful signal.
miner feedbackreads both, with rejected comments weighted higher in the next batch's prompt.
Verifiers
A verifier is a Python function over a cart_state snapshot:
Two skills handle the lifecycle:
/create-verifiers {site}reads the task from Helix, optionally analyzes a recent benchmark run'scart_state(so the verifier reflects what real successful carts look like, not a guess), pulls the catalog, and writessites/{site}/verifiers/verifier_{task_id}.py. It also maintains the per-sitehelper.pywith reusable predicates (e.g.,is_product_type_match,cart_total, etc.) so verifiers don't redefine questions like "Is a tee actually a tee, or is it a 'short sleeve top'?"./evaluate-verifier {site} {id}is a separate audit pass. It looks for: overly strict matching (e.g., comparing"Navy"to"navy heather"with==), missing normalization (price strings vs. floats, trailing whitespace in option values), partial-completion bugs (verifier passes when only 2 of 4 required items are in cart), and false negatives (rejects a valid completion because of variant naming).
The two-skill split matters: writing and reviewing are different cognitive modes, and a single agent doing both will have blind spots on its own work. Running /evaluate-verifier as a separate invocation surfaces ~25% of verifiers with at least one issue worth fixing.
After verifier registration, a one-shot verification benchmark (runs=1) replays one of the passing CUA traces against the new verifier. If it passes, the task transitions to ready_for_review automatically. If it fails, the verifier is wrong and gets revised.
The Live Sites Decision
In this process, we benchmarked exclusively against live Shopify storefronts. We considered the alternative: locally cloned snapshots, served from a static/replayed environment, and decided against it. There were several trade-offs involved:
Advantages:
Distribution match: On live sites, the agent is evaluated on exactly the surface it will see in production — no replay drift, no missing JS, and no stale CDN behavior — thereby eradicating the sim2real gap.
Inventory truth: A task that says "buy the cheapest Vital Seamless tee in Black, size M" is only meaningful if the catalog actually reflects current stock. A clone freezes inventory at capture time; tasks rot in days.
Free coverage of edge cases: Real sites have A/B tests, popovers, geo-redirects, currency switchers, lazy-loaded carousels, and CAPTCHA challenges. These are features of the benchmark, they are exactly the things CUA agents struggle with. A clean clone removes them.
Storefront API as ground truth: Shopify's GraphQL gives us programmatic cart state without scraping. This works because the cart is real.
Disadvantages:
Non-stationarity: A task that’s live-site valid on Monday may be invalid on Friday because the product sold out. We mitigate by (a) re-fetching
catalog.jsonbefore every mining session and (b) failing tasks that hit out-of-stock in verification.Cost: Browserbase + residential proxy + N=5 runs on a 50-task batch is real money. ~$0.30 per CUA run, scaling linearly.
Rate limits and bot detection: We rotate residential / ISP / datacenter proxies (
PROXY_URL_*env vars,-proxyflag on the runner) to stay under thresholds. Some sites still block; we drop those.Reproducibility: A run from six months ago cannot be exactly re-executed. We capture
cart_state, full action logs, and screenshots, which is enough for post-hoc analysis but not for replay-based experiments.Ethics & ToS: Adding items to a real cart and abandoning is normal user behavior. We don't checkout, but we do consume merchandiser inventory holds. This is probably fine at our volume; it would not be at training-data volume.
For training (vs. evaluation), a hybrid is probably right: live mining to surface hard tasks, then a one-time replay capture to freeze them for high-volume training. We haven't built that yet.
The QA Review Pipeline
The state machine for a task:
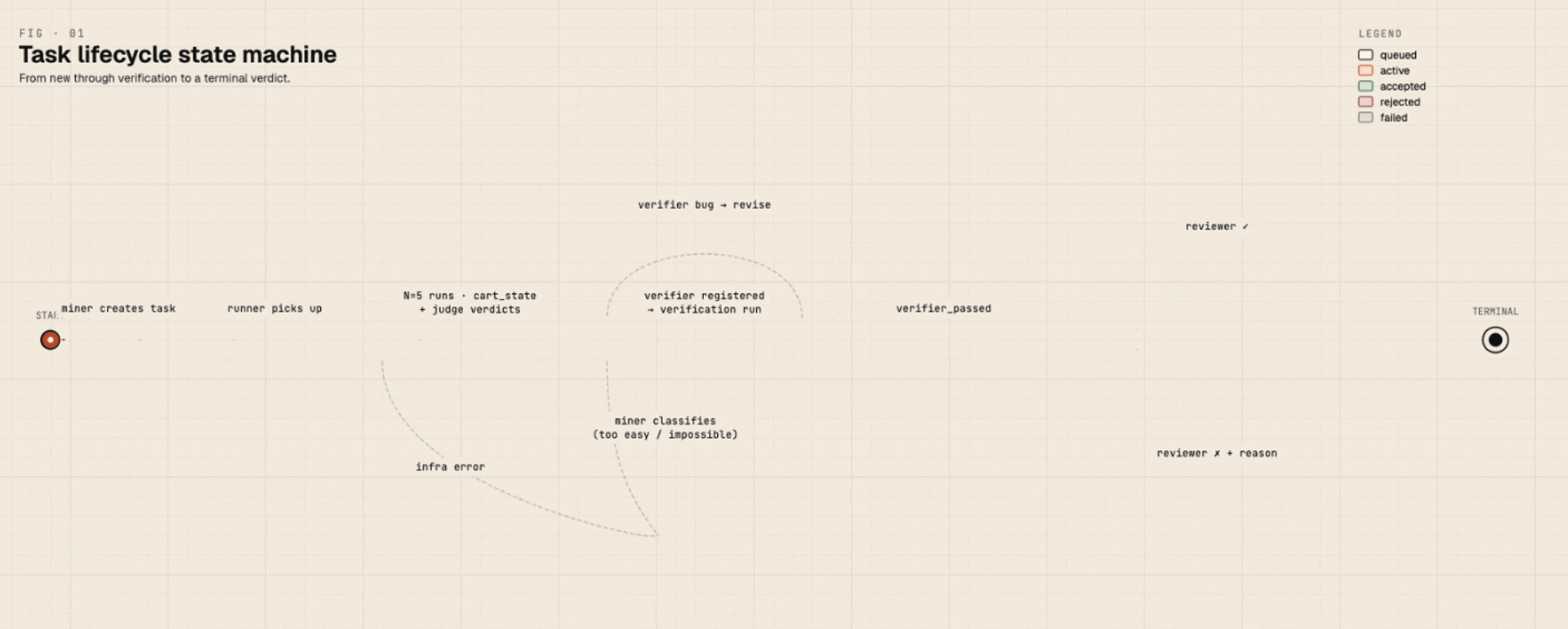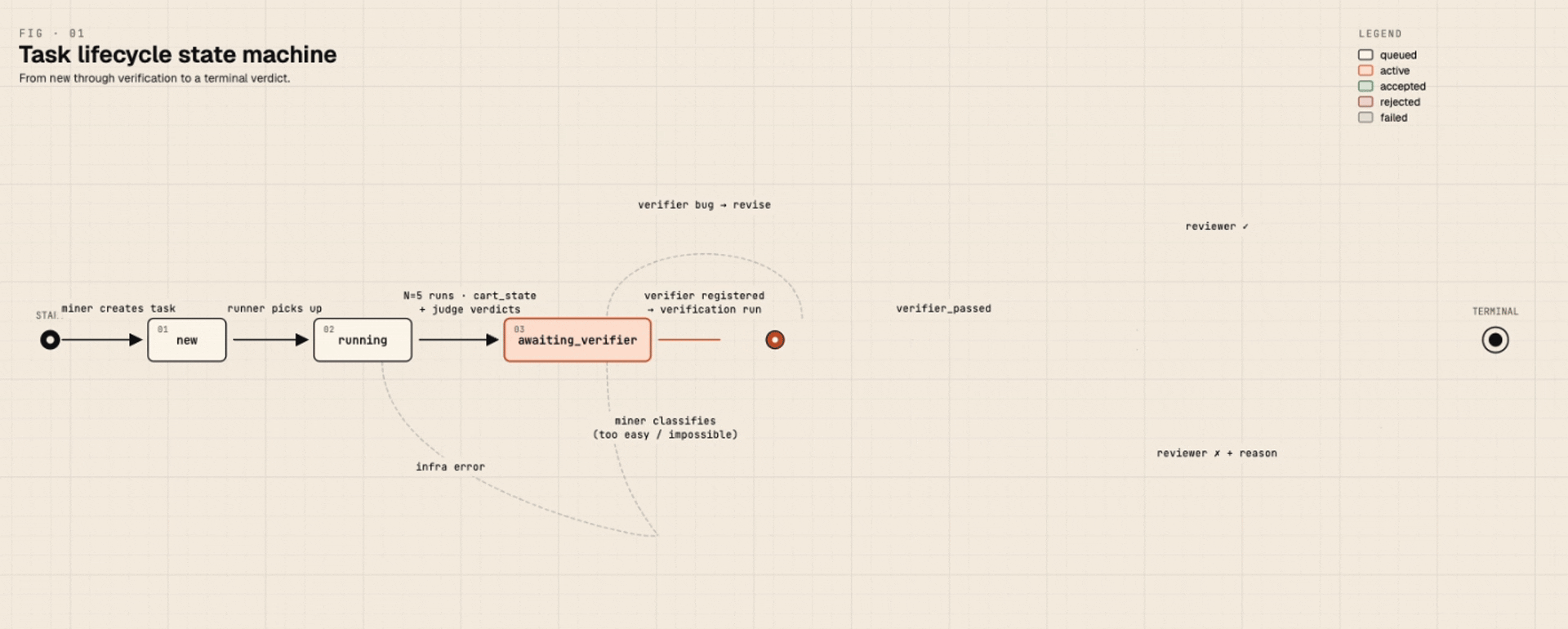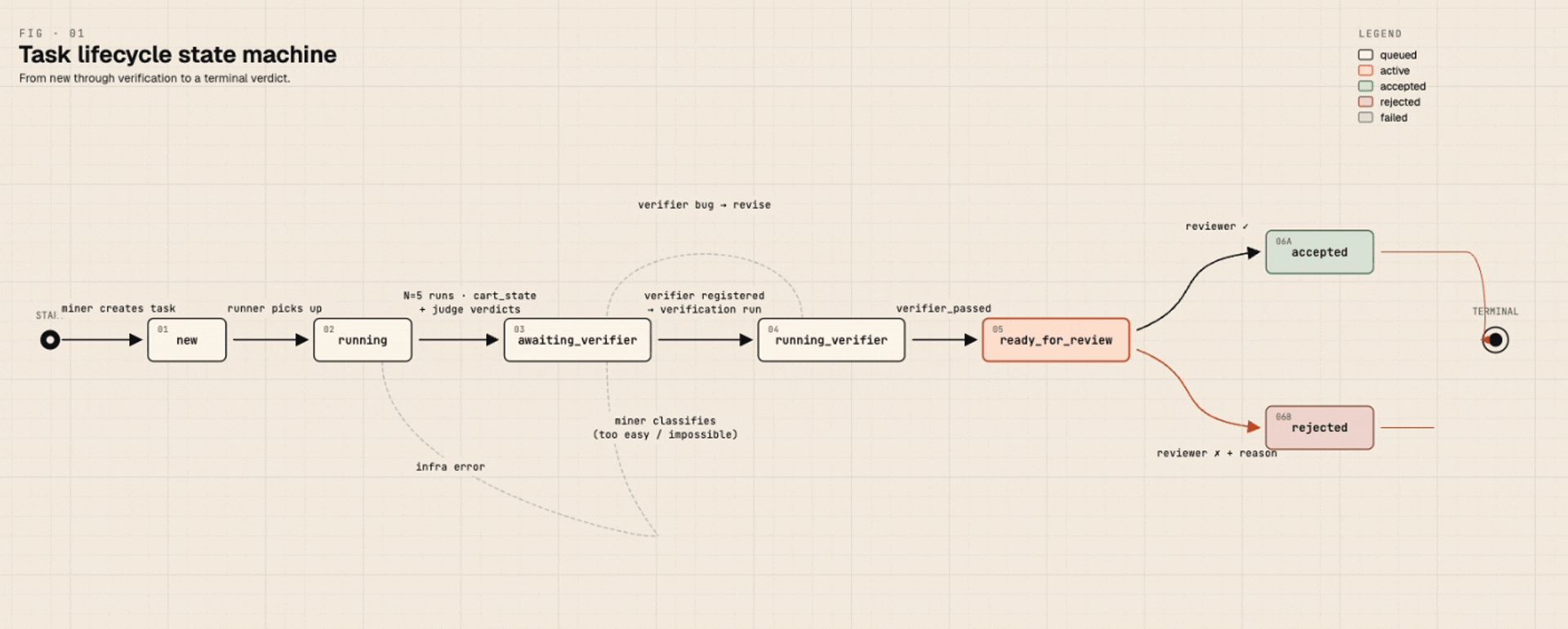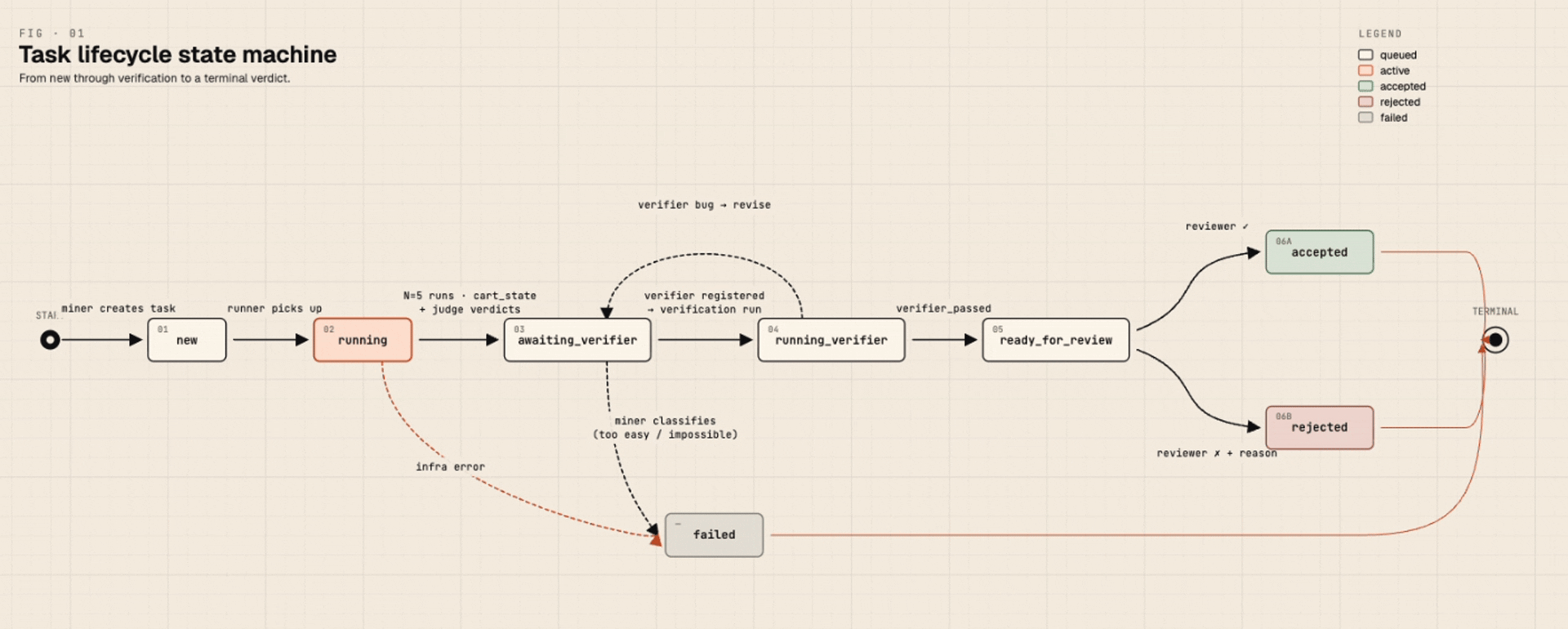
Human review happens in the Helix front-end: a reviewer sees the task prompt, the cart state of one passing run, the verifier code, and the benchmark pass rate. They accept (with optional constructive comments), reject (with reason), or punt back. The miner reads accepted and rejected comments. Comments on accepted tasks are nudges, not just rejections, and they shape the next batch's choices.

Actor Sequence Diagram

Swimlane Diagram
TRACE: capability-gap analysis

TRACE-inspired theme-coding pipeline
Mining at random near the failure boundary wastes most of the search. The failure rate alone doesn't tell you which capability deficit caused the failure, and the mining batch you'd write to attack each is different.
The framing comes from Stanford's TRACE (Kang, Suresh et al., 2026): the reward signal doesn't reveal which capabilities the agent lacks. TRACE clusters failures into capability categories, then trains LoRA adapters on synthesized environments for each gap. We don't train adapters — we borrow the identification step.
The Identification Step
We conduct three passes (with Opus 4.6 as the audit model):
Open coding: One LLM call per run produces 3–6
snake_casecapability codes with step-level evidence (different prompts for fails vs. passes). No fixed taxonomy; codes are bottom-up.Theme curation: A human-in-the-loop pass clusters the raw codes into 8–12 themes per model, each with a description and a diagnostic question. Themes carry over between models when the same gap recurs.
Theme assignment: One LLM call per (run × theme) pair answers yes/no with an evidence quote. We render per-theme prevalence and a contrastive gap: P(present | fail) − P(present | pass). The contrastive gap is what filters out false positives.
Once the capability gaps are identified, the miners can then generate tasks that exploit those gaps.
Future Work
Our fundamental goal is to create systems that allow for autoscaling post-training data (environments, tasks, verifiers, etc.) for frontier models.
In building this system, we tested out and scaled up two ideas: (a) an automated task miner, inspired by the principles of UED, and (b) a rigorous QA process involving augmenting the derived tasks with human annotators.
In generating this task dataset for Yutori’s post-training efforts, this project was specifically focused on browser-use. Our next step is to expand to other domains: computer-use and tool-use, especially for enterprise software use cases.
If you're working on RL environments for frontier labs (autoscaling, capability targeting, programmatic verification, the engineering side of the environment supply chain, etc.), we would love to hear from you.
